

Ijraset Journal For Research in Applied Science and Engineering Technology
Unmasking the Shadows: A Multi-Dimensional Approach for Cyberbullying Detection in Social Media Networks
Authors: Patnana Sayesu
DOI Link: 55214
Certificate: View Certificate
Abstract
Cyber bullying refers to the use of electronic techniques of intimidation. Historically challenging, there has been a growing awareness of the repercussions for young people. Teenagers and young adults who spend time on social media sites are an easy target for bullies because of the platform\'s conducive nature to harassment and threats. We can create algorithms that can automatically identify cyberbullying material and distinguish between the language styles of cyberbullies and their victims with the use of machine learning techniques. Over the last decade, social media has seen explosive growth, which has benefits and drawbacks. As the number of social media sites and apps continues to grow, more and more people are able to connect with one another online. directly, ignoring cultural and economic contexts While there are numerous positive outcomes associated with social media use, none exist at this time. The increase of hate speech over the last several years is a special issue that has surfaced. The use of foul language is the major component of hateful statements. Online networking use It might be used to refer to anybody or anything at all. collective of like-minded people. The methods we use to deal with hostility and the steps we take to mitigate it were detailed in this study. People\'s instantaneous expressions of wrath and animosity on social media are harmful to the sentiments of others. In-depth investigation on the handling of The most accurate machine learning and natural language processing techniques were used to choose the model used to exclude hate speech.
Introduction
I. INTRODUCTION
Cyberbullying is described as the purposeful infliction of emotional, psychological, or bodily harm to others by the use of objectionable material such as intimidation, using OSN services to send or post messages, insult, and hate. In recent years, social media has taken over as the main channel for distributing ideas throughout the globe. based on the reference. Although social networking is a reliable platform, the volume of content published and discussed makes it difficult to check every comment in one sitting, which leads to an increase in hate speech. Due to the rapid expansion of networking on websites and social media, people now communicate directly with one another across ethnic and economic divides. Another way to characterise hate speech is as an emotional notion. social media users using language that is obscene and nasty may be considered a kind of hate speech. It can apply to any single or particular group of the people who share interests. In this research, we described how we cope with vitriol and, in large part, how to lessen it. Hate speech has escalated dramatically in recent years. In reality, it has worsened since then, the all of the work and communications has conducted online, the COVID-19 pandemic-related shutdown. More people are using social networking sites like Facebook, Twitter, and Instagram. of diverse ages, origins, and interests, and very frequently. Several of the website’s vitriol has been reported may be found here.
These platforms offer a free forum for users to express their views and share or transmit their ideas throughout the globe, but the sheer volume of postings and communications exchanged makes maintaining content control nearly difficult. Facebook has put in place an array of community norms to address abuse, cyberbullying, unlawful activity, assaults against women and violence against celebrities. Facebook and Twitter both also has several rules that might help someone who has been the victim of social abuse.
Hate speech not only causes turmoil and friction among diverse groups, but it also causes real-world problems. This study defines hate speech and provides several instances of how hate speech happens. It is mostly concerned with addressing hate speech on Twitter. The data pre-processing comes next. It then goes on to describe the approaches used on dataset, including pattern extraction, sentiment evaluation, semantic analysis, and the Unigram feature. It contains charts and figures that show the level of precision and accuracy reached for various models.
II. PROBLEM STATEMENT
Cyberbullying has emerged as a significant societal issue with the increasing use of online social networks. As individuals of all ages spend more time on these platforms, the potential for harassment, intimidation, and abuse has also amplified. The detrimental impact of cyberbullying on mental health, self-esteem, and overall well-being necessitates the development of effective detection and intervention strategies. This study aims to address the pressing need for a method for detecting cyberbullying based on deep learning designed particularly for digital social networks.
Despite numerous efforts to combat cyberbullying, the dynamic nature of online platforms poses a significant challenge. Traditional rule-based approaches and keyword matching techniques often fail to capture the nuanced and context-dependent nature of cyberbullying. Additionally, the sheer volume of user-generated content makes manual monitoring and intervention practically impossible. Consequently, automated methods are crucial for detecting and addressing cyberbullying instances in a timely manner.
While a number of machine learning methods have employed in cyberbullying detection, deep learning has shown promise in capturing complex patterns and dependencies within textual data. Deep learning models, transformers, have demonstrated superior performance in tasks involving natural language processing, such as text categorization and sentiment analysis. However, their application to cyberbullying detection in the context of online social networks remains underexplored.
This study aims to fill this void by creating a cyberbullying detection system powered by deep learning that can efficiently examine user-generated content on social media platforms. Convolutional neural network (CNN) and LSTM (long short-term memory) network models, as well as transformer models like BERT, will be used in the proposed framework (Bidirectional Encoder Representations from Transformers). The framework will learn to recognize several types of cyberbullying — written, visual, and auditory — by being trained on a vast collection of labelled examples. Contextual information, such as user profiles, social network ties, and past encounters, will also be taken into account by the framework. By using a more all-encompassing strategy, we can improve cyberbullying detection by minimizing the number of false positives and negatives.
III. OBJECTIVES OF THE STUDY
This project's main objective is to ascertain the cyber bullying through social media like the offensive statements. Here we have considered the monitoring of hate speech on social media platform and to detect this we have implemented machine learning algorithms. Develop a comprehensive understanding of cyberbullying: The study aims to explore and analyse different forms of cyberbullying, including text-based, image-based, and video-based bullying behaviors. By examining existing literature and real-life instances of cyberbullying, the research seeks to gain a thorough knowledge of the issue and its effects on people and society.
Build a dataset for training and evaluation: The study intends to collect a diverse and representative dataset comprising various instances of cyberbullying and non-cyberbullying content from different online social networks. This dataset will be used to train and evaluate the deep learning-based cyberbullying detection framework.
Design and implement a deep learning model: The research advances an effective A deep learning approach to detecting cyberbullying. This involves selecting appropriate deep learning architectures. Investigate feature engineering and representation learning: The study seeks to explore different techniques for feature engineering and representation learning specifically tailored for cyberbullying detection. This may involve analysing text sentiment, linguistic patterns, visual content analysis, and contextual information to develop robust features that capture the nuances of cyberbullying Behavior. Evaluate and validate the proposed framework: The research intends to evaluate the efficiency and efficacy of the created deep learning-based system for cyberbullying detection. This involves performing comprehensive research using the gathered data and comparing the outcomes using current the most recent methods. To determine whether the framework is successful, performance criteria including precision, recall, precision, accuracy, and F1 score will be taken into account. Explore interpretability and explain ability’s the study aims to investigate methods for interpreting and explaining the decisions made by the model of deep learning. Recognising the causes behind the model's predictions can provide insights into identifying cyberbullying indicators and increasing transparency, thereby facilitating trust and acceptance of the framework.
IV. PROJECT METHODOLOGY
A. Convolutional Neural Network (CNN)
- Step1: operation with convolutions
Our process starts with a convolutional operation. Feature detectors, which serve as filters for neural networks, will be discussed at this stage. Map features, their settings, the detection of patterns, the naming of layers, and the display of the findings will also be discussed.
2. Step (1b): ReLU Layer
The second stage of this procedure will make use of the corrected linear unit, or relook. We'll Examine the function of linear in convolution neural networks and talk about Relook layers. Although it is not necessary to attend a quick course to increase your knowledge in order to understand CNN's, it wouldn't hurt.
3.Step 2: Pooling Layer
Pooling will be discussed, and its operation will be detailed, below. In this scenario, however, the idea of maximum pooling will be essential. We will, however, explore other method s, such as median (or total) pooling. In order to help you fully appreciate the idea, this section will finish with an example of an animated interaction tool.
4. Step 3: Flattening
In order to transition between pooling and flattened layers when utilizing convolutional neural networks, below is a brief description of the flattening process.
5. Step 4: Full Connection
The previous section's material will carry over into this one. You'll have a better grasp of convolutional neural networks and how the "neurons" they generate may be taught to recognise and categorise images.
Summary: Then, we'll put everything into context and give a succinct overview of the concept covered in this part. Check out the additional tutorial where SoftMax is a and Cross-Entropy are addressed if you think it will help you (which it probably will). Even while you are not necessary to know these concepts for the course, it will be very beneficial for you to do so because you will likely run across them when using convolutional neural networks.
B. Long Short-Term Memory (LSTM)
Different from other RNNs, "Long- and Short-Term Memory Networks" (LSTMs) can identify long-term dependencies. Since their first description by Hochreiter and Schmid Huber (1997), several authors have elaborated on and popularized them. They are now widely used because of their efficacy in treating a wide range of illnesses.
Long short-term memory (LSTM) systems were developed to address the problem of over-reliance. Not only are they not driven to study, but long-term memory is not even a skill they need to develop. In general, recurrent neural networks are made up of a set of modules that are used repeatedly. In typical neural networks, a tan h layer would be the only complexity added to this repeating module.
C. Logistic Regression
Around the start of the 20th century, the biological sciences were the first to employ logistic regression. After that, it served a range of social science objectives. When a dependent (target) factor is categorical, logistic regression is utilised.
For example,
To determine whether a spam email is (1) or (0)
whether or not the tumour is cancerous (1) or not
Think about a situation in which we must determine if a specific email is trash or not. If linear regression is employed to address this issue, we must first define a threshold to be able to do classification. Assume that the data point is really classified as malignant but is treated as non-malignant; the expected continuous number is 0.4, and 0.5 is the cutoff. Currently, this might have severe results.
It is clear from this example that linear regression is not a good fit for classification tasks. The limitless character of linear regression gives rise to logistic regression. They only include values between 0 and 1.
Goals and illustrations using logistic regression:
Logistic regression is a well-liked ML method for situations involving two classes, or "binary classification.". These include predictions like "this or that," "yes or no," and "A or B.”
Determine a correlation between attributes and the likelihood of certain outcomes by using logistic regression to calculate event probabilities.
One example is a model that uses the student's number of study hours together with the pass/fail values for the test's response variables to predict the student's likelihood of passing or failing the exam.
Logistic regression's ability to accurately anticipate future outcomes, such as reduced costs/losses and increased return on investment in marketing activities, may help businesses improve their corporate strategy and reach their objectives.
An online shop would want to know whether or not a certain customer will take advantage of the offers before distributing expensive promotional offers to consumers. For example, they can inquire as to whether the client would be either a "responder" or a "nonresponse." This is a marketing term referred to as likelihood to react modelling.
In a manner similar to a credit card firm will create a model to make decisions. if it wants to provide a customer a new financing card and will make an effort to predict whether the consumer would default on the loan based on variables such as yearly earnings, monthly payments on credit cards, and the frequency of defaults. This is referred to as defaults propensity modelling in the banking industry.
Logistic regression applications:
The expanding use of logistic regression has immensely benefitted online advertising since it enables marketers to predict the percentage possibility that a certain website visitor would click on a particular advertisement.
• Additionally, you may apply logistic regression in:
• determining sickness risk factors and organising preventative measures in healthcare.
• Apps that forecast the weather and the amount of snowfall.
• Voting software to predict if users would back a certain candidate.
Life insurance calculates the probability that the policyholder would die before to the policy's expiration date by considering the insured's gender, age, and health status, among other factors.
In banking, the annual income, default history, and current debts are used to predict the likelihood of a loan request being approved or denied.
comparing linear regression with logistic regression:
The primary distinction between logistical regression and the linear model is that the output of logistic regression is constant whereas the output of linear regression is continuous.
A dependent variable's result in logistic regression has a constrained range of potential values. However, the outcome of a linear regression is continuous, meaning that there are an endless number of potential values.
Logistic regression is used when the answers to a variable may only be yes or no, true or untrue, or pass or fail in the real world. For continuous response factors like work hours, height, and body mass index, linear regression is used.
Exam results and student study time data, for example, may be used to forecast using logistical regression or a linear regression model.
Logistic regression can only be used to make predictions within certain ranges of values. Success or failure in school may therefore be predicted using logical regression. Linear regression may be used to foretell where the student would fall on a scale from 0 to 100, since its predictions are unchanging like range integers.
D. Naive Bayes
Whenever a classification issue arises, experts turn to the Bayes naïve classification algorithm—a probabilistic machine learning (ML) model. The Bayes theorem is the classifier's underlying mathematical framework.
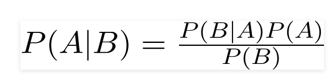
After event B has occurred, the probability of event A may be calculated using Bayes's theorem. Here, A is the hypothesis, and B is the evidence in favour of it. In this scenario, it is assumed that predictors and attributes are unrelated. In other words, someone else's actions won't change just because you share a quality with them. As a result, it is deemed naïve.
Let's look at an illustration to see what I mean. You'll find some weather-related training data and the corresponding goal variable "Play" below (which indicates if playing is possible). Now we have to categorise whether or not people will play the game based on the weather. Let's put an end to it by following these steps.
Step 1: Create a frequency distribution using the dataset.
Step 2: You may make a likelihood table by calculating probabilities such as Overcast probability = 0.29 and Playing probability = 0.64.
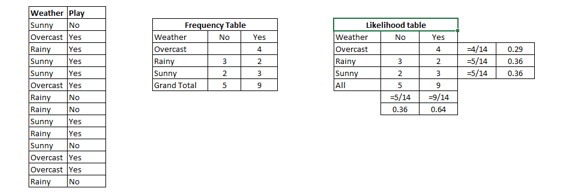
Step 3: To calculate the subsequent probability for each category, use the naïve Bayesian procedure. From a forecast, the grouping with the greatest posterior probability emerges.
Problem: Even in good lighting, gamers will still turn up. Is this claim true?
Using the just-described posterior probability technique, we can find a solution.
The probability of it being sunny on a given day, P (Yes | Sunny), is calculated as follows: (Sunny)
The probabilities of sunny and yes are respectively 0.33 and 0.36 for the current conditions, and 0.64 for the future.
The more accurate probability is now P (Yes | Sunny) = 0.33*0.64/0.36 = 0.60.
Naive Bayes uses a similar approach to predict the probability of different classes based on a number of inputs. Because of the large number of categories, text categorization is the primary application of this technology.
- Prediction of the class of test data set is rapid and easy. Furthermore, it is excellent in multi-class prediction.
- A classifier based on Compared to other designs, such as logistic regression, the naive Bayes model performs more effectively if its presumption of independence is valid and needs less training data.
- Categorical input variables outperform numerical input variables in terms of performance. Bell curve, which serves as which is a strong assumption, indicates that a distribution of normality is assumed for numerical variables.
E. Applications of Naive Bayes Algorithms
- Real-time Forecast: The naive Bayes classifier is rapid and eager to learn. Therefore, it might be utilised for instantaneous forecasting.
- Multi Class Prediction: It's common known that this method may accurately foretell a wide variety of categories. Several different kinds of target variables' probabilities may be predicted.
- Text Classification/ Spam Filtering/ Sentiment Analysis: The naive Bayes classifier are often used in text categorization and have a higher success rate than other techniques since they function better in multi-class scenarios and adhere to the independence condition. As a result, it is often utilised in the detection of favourable or adverse customer views, sentiment evaluation (in social networking analysis), and spam filtering (to identify spam e-mail).
F. Random Forest
Machine learning techniques for dealing with classification and regression problems include the random forest approach. It employs ensemble learning, a technique for handling challenging issues that combines a number of classifiers.
The random forest method offers a wide range of potential decision trees. The random forest approach creates a "forest" that is then trained via bagging or bootstrap aggregation. The accuracy of machine learning algorithms is improved by the collective meta-algorithm known as bagging.
Many different kinds of decision trees may be generated using the random forest technique. The "forest" is established by training using the random forest method and either bagging or bootstrap aggregation. In order to improve the precision of machine learning algorithms, the bagging collective meta-algorithm was developed.
The random forest technique is an improvement on the choice tree strategy. Overfitting the data and loss of accuracy are both reduced. Unlike Scikit-learn, which requires various package settings before producing any predictions, this one doesn't.
The Random Forest Algorithm's Features:
- When compared to the decision tree technique, it is shown to be more precise.
- It offers a practical method for dealing with data gaps.
- Without hyper-parameter tuning, it can still provide an acceptable prediction.
- The problem of overfitting in decision trees is fixed.
- At each branching point of a randomly generated tree, a different set of characteristics is chosen at random.
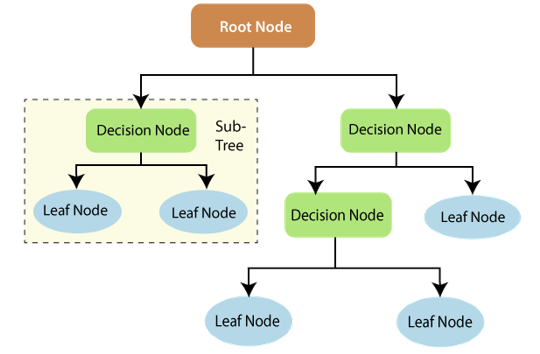
The decision trees at the heart of every random forest method. Decision trees are a kind of decision-making aid that take the form of a tree diagram. We'll discuss random forest approaches and how to construct decision trees.
There are three pieces to a decision tree: the decision nodes, the branching nodes, and the root nodes. Using a decision tree method, a training dataset is split into branches, and those branches are further broken down. This process is done until greenery appears. There is no way to divide the leaf node any further.
The nodes of the decision tree stand for the characteristics that are considered while making a prediction. Decision nodes act as connectors between different paths. The figure below illustrates the three possible types of decision tree branches.
Decision trees may be better comprehended via the lens of concept operation data. The foundation of a decision tree is entropy and data analysis. By delving into these basic concepts, we may better grasp the reasoning behind the building of decision-making chains.
The degree of uncertainty may be quantified by entropy. Information gain is the amount by which a set of independent variables reduces the variance in the target variable.
Information acquisition refers to the process of gaining insight into the characteristics of a target variable via the examination of its constituent parts (features) (class). Gain in knowledge is determined by summing the entropy of all Y variables and the conditioned mobility of Y. (given X). The entropy of Y is decreased due to the conditional entropy in this case.
Gathering data is an important part in training decision trees. It helps calm these plants' nerves. Large information gains result in a significant reduction in ambiguity (information entropy). When building decision trees, branch splitting is a crucial step that requires both information gain and entropy.
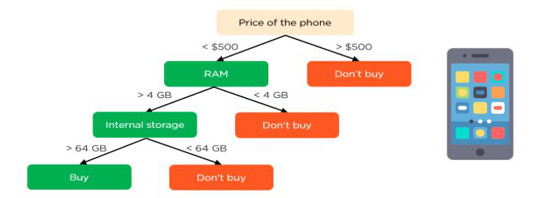
Consider this simple decision tree. Let's pretend we're trying to predict whether or not a certain customer would purchase a mobile phone. The features of the phone are what ultimately sway his choice. Decision tree used as an illustration in the research.
The option's root node and choice node stand in for the aforementioned mobile device characteristics. The result of a purchase is shown in the leaf node. RAM, storage space, and cost are the primary determinants (random access memory). As can be seen in the photo, a tree of options will be shown to you.
Applying decision trees in random forest
The choice tree technique is an alternative to the random forest approach, which uses a predetermined seed to group nodes. Random forests use the bagging method to create accurate predictions.
Instead, then utilising a single sample, bagging makes use of several data points (training data). A training dataset's traits and projections are based on observations. According to the training information that the algorithm for random forests receives, decision trees can give a variety of results. The ultimate output will be determined by its highest ranking among these outputs.
We can still use our original example to show how random forests work. There will be more than one choice tree in a random forest. Assume there are a total of four decision trees. The initial training data, which contains using the phone's attributes and observations, four root nodes will be produced. The base nodes are four aspects of a product's pricing, internal storage, camera, and RAM that may affect a customer's decision. The nodes will be divided into groups by a forest formed at random by choosing characteristics. The results of each of the four trees' predictions will be used to determine the final forecast.
V. SOFTWARE DESIGN
A. SDLC: Software Development Life Cycle
For the cycle associated with creating software of our project, we have adopted the waterfall a paradigm in recognition of its meticulous rules and regulations.
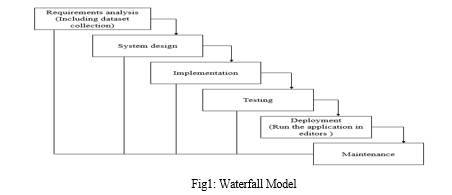
- Requirement Gathering and Analysis: In throughout this time, every prospective requirement for the requirement specification of requirements synthesises into one document an illustration of the system that will be was underway.
- System Design: While hearing this phase, every aspect of the system design is developed and additionally the necessary specifications during the first phase are investigated. This system design not merely reveals the overall system architecture yet also aids when determining the hardware and system requirements.
- Implementation: An architecture of the method will be originally developed on distinct programmes as known as units featuring the modified system design; In this units are then investigated in the process immediately follows. A process of building every unit as well as determining its functionality as the process called unit testing.
- Integration and Testing: A whole arrangement the combination occurs following the creation of each unit during the beginning rhythm is finished being reviewed. Following emancipation, the complete architecture is examined for flaws alongside vulnerabilities.
- Deployment of System: A substance's utilisation necessitate place throughout a consumer's When testing for both functionality and non-functionality concludes, the products are removed from the environment or made available for purchase.
- Maintenance: Regarding a client environment, numerous problems may arise for resolving the specific problems patches are released. The product additionally became released in some upgraded versions. Maintenance is done to bring about the previously discussed modifications in the consumer's habitat.
VI. FEASIBILITY STUDY
During the feasibility of the idea at this time undergoes evaluation in addition a really straightforward business proposal structure for the project in addition to others cost estimates becomes available. The strategy involving system analysis must be conducted examine your recommended system's viability. Through carrying out this, it will be ensured that The recommended fix is not going to cause a strain on the company's finances. For the feasibility study to be useful, it is essential to understand the basic system requirements.
The following are crucial parts of a successful feasibility study:
- Economic Feasibility: The intention of this inspection is to assess any prospective monetary impact of the system on the organisation. Because the firm is left with a restricted amount of money available for system research and development, costs must be defended. The majority of the technologies employed were widely available, therefore the system's development stayed within the budget allotted. The only costs incurred were for the purchase of customised items.
- Technical Feasibility: The purpose of this research is to assess the system's technical requirements or feasibility. It is essential that the new system does not put an undue burden on the existing technological means. The system will place heavy requirements on the client's current technological infrastructure. Requirements should be kept low to allow the proven system to be deployed with few, if any, changes.
- Social Feasibility: The objective of that research is to gauge how well-liked the system is by its users. This includes giving consumers the information they need to efficiently use the system. Instead of making users feel threatened or uncomfortable, the system must make them feel like they are necessary. The only characteristics influencing the manner in which users are introduced to and get familiar with the system determine how acceptable the system is. As the system's primary user, it's crucial to boost user confidence so they can offer helpful criticism, which is strongly encouraged.
VII. DETAILING THE REQUIREMENTS FOR THE SYSTEM
A. The Criteria, Both Functional and non-Functional
An essential stage in figuring out if a venture involving software either a system Expect to be prosperous is requirement analysis. Functional & Non-functional specifications are the two categories into which requirements are typically divided.
- Functional Requirements: The end user has requested a minimum set of features for the system, which are specified as criteria to be met. These criteria are outlined in the contract, and it is mandatory for each feature to be incorporated into the system. These criteria are expressed in terms of input requirements to enhance the system, the corresponding actions taken, and the expected outcomes. These criteria represent the user's explicit requirements, which differ from non-functional requirements as they are directly observable in the final product.
Examples of practical necessities:
a. Those must authenticate themselves on every occasion they log into the system.
b. If there is a cyberattack develops, turn the system disconnected.
c. The appreciation of currencies email is communicated on behalf of Each individual who claim first registers on an exclusive software platform.
2. Non-functional Requirements: These standards could be in the year a nutshell these are the following quality requirements: the system needs to stick as per the project agreement. These standards could be supplied the enactment of a different hierarchy of importance an entirely distinct degree is contingent on the undertaking. Non-behavioral requirements are another name for them.
That they primarily speak about point at issues including but not limited to
a. Adjustability
b. Dependability
c. Justifiable
d. Trustworthiness
e. Dilatability
f. Accomplishment
g. Reusability
h. Elasticity
Examples of these non-functional requirements include:
- Email ought to become sent no sooner than 12 hours following the action.
- Every request should be carried out in ten seconds or fewer times
- The website should load in three seconds irrespective of whether it receives more than 10,000 visitors on a single occasion.
B. Software And Hardware Requirements
- Hardware
Operating system : Windows 7 or 7+
Random Access Memory : 8 Gigabyte(GB)
SSD or a Hard Disc : in excess of 500 GB
Processor : 3rd generation Intel or Ryzen with 8 GB of RAM
2. Software
Software’s : Python version 3.6 or above
IDE : PyCharm.
Framework : Flask
C. System Design
- Input Design
The data in its original form in the context of a system of information, input is the whole thing that is processed to create manufacturing. Designers implementing the input must consider several submission forms, such as PC, MICR, OMR, etc.
Their level on workmanship throughout the input dictates the process production as a result. Input forms and screens that are well-designed have the qualities listed below:
- Effectively placing it away, recording, and retrieving information are only a few examples of the precise purposes it should serve.
- The film facilitates correct and accurate fulfilment.
- It should be uncomplicated for people to complete and sympathise.
- Its top priority should be user consideration for the details, consistency, and simplicity.
- All of the preceding objectives get accomplished as they relate to - using an understanding of fundamental design fundamentals.
- Which system-level inputs are crucial?
- the manner in which consumers adapt to numerous form and screen components.
Victory related to the Input Design:
The aforementioned are the input design's objectives.
- Turning down the input thickness;
- Growing novel gathering of statistics methods / information sources to feed collecting info;
- Crafting Entering information viewing angles, input data records, user interface displays, etc;
- Implementing confirmation measures;
- Supplying advantageous opinions penalties.
2. Output Design
Output design is the most significant obligation across all of the systems. Developers are inclined to focus on the most important output before designing output all stripes. Researchers also consider outcomes of controls and prototypes about the report layout.
Victory with respect to the results of Design:
Their intended objectives of input design comprise as afterwards was:
- Creation of innovative designs complete their indispensable function along with discontinue the undesirable result.
- Conceive of an output that complies with the needs of the intended user.
- To assemble the right measurement of output.
- Generate their result and deliver it to the appropriate recipient in the appropriate format.
For achieving the intended objectives on time so that they can be used to make wise judgements.
VII. IMPLEMENTATION
- This section gives a brief summary of existing methods and challenges associated with cyberbullying detection. Traditional approaches have relied on rule-based techniques and keyword matching, which often fail to capture the complex nature of cyberbullying. Machine learning's subset of deep learning gives an overview of promising solution by leveraging neural networks to learn patterns and features directly from the data.
- An essential step in developing a deep learning-based framework is the collection and preprocessing of data. This study proposes the acquisition of a large dataset containing instances of cyberbullying from various online social networks. The collected data should encompass different forms of cyberbullying, including text, images, and multimedia content. To ensure the quality of the dataset, manual annotation and labeling processes should be conducted to identify instances of cyberbullying accurately.
- The core component of the proposed framework is the deep learning architecture. A general description of the architecture is provided in this section. This architecture typically comprises of many different layers of neural networks. Common architectures can be modified to accommodate many types of data, including Recurrent and convolutional neural networks (RNNs and CNNs, respectively) input data, such as text or images. The procedure for schooling includes providing nourishment the model with a labelled dataset along with iteratively Raising it network's weights with optimize its performance.
- To effectively detect cyberbullying, the deep learning model needs to extract relevant features from the input data. For textual content, techniques such as word embeddings (e.g., Word2Vec or GloVe) can be employed to convert words into numerical representations that capture semantic relationships. For images and multimedia, pre-trained deep neural networks, such as VGG or ResNet, it may be employed to draw out advanced visual features.
- Which section outlines their deep learning model's training and assessment procedure. educational institutions, encouragement and testing sets are created from the obtained dataset. The training set is used to teach the model, while the validation set is used to assess the model's accuracy at regular intervals and prevent overfitting. Using the validation set, the model's ability to identify instances of cyberbullying was evaluated. Using Ratings as a Metric The model's efficacy is measured in a variety of ways, but most notably via its accuracy, precision, recall, and F1 score.
- The results of the tests conducted using the proposed framework are presented in this portion of the research. As soon as comparing the deep learning model's goods and services against existing approaches and benchmark datasets. The results highlight the framework's effectiveness in accurately detecting instances of cyberbullying across various types of content on online social networks. Furthermore, the study discusses any limitations or challenges encountered during the experiments and suggests potential avenues for improvement.
- The study concludes by summarizing the key findings and contributions of the proposed deep learning-based cyberbullying detection framework. It emphasizes the significance of leveraging advanced machine learning techniques to combat the growing issue of cyberbullying on online social networks. The framework's potential applications in real-world scenarios, such as content moderation and proactive intervention, are also discussed. Finally, the study calls for further research and development in this domain to enhance the effectiveness and scalability of cyberbullying detection systems.
- This study presents a comprehensive cyberbullying detection framework for online social networks the use of deep learning. By leveraging a power about neural networks and advanced feature extraction techniques, the proposed framework offers a promising solution to tackle the challenges associated with cyberbullying. The results obtained from experiments demonstrate the framework's effectiveness in accurately detecting instances of cyberbullying across different types of content. It is hoped that this research will contribute to creating safer and more inclusive online environments for users worldwide.
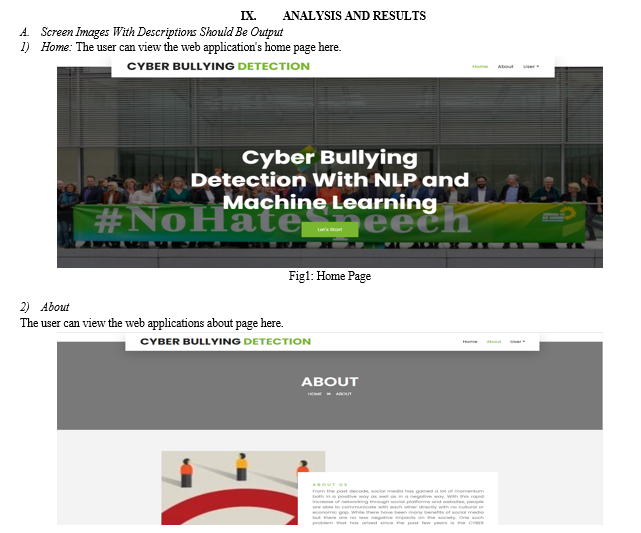
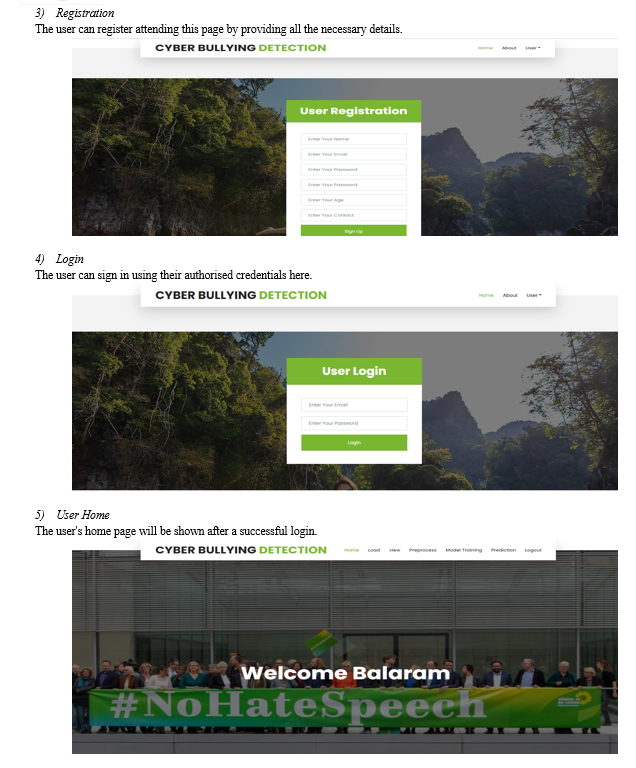
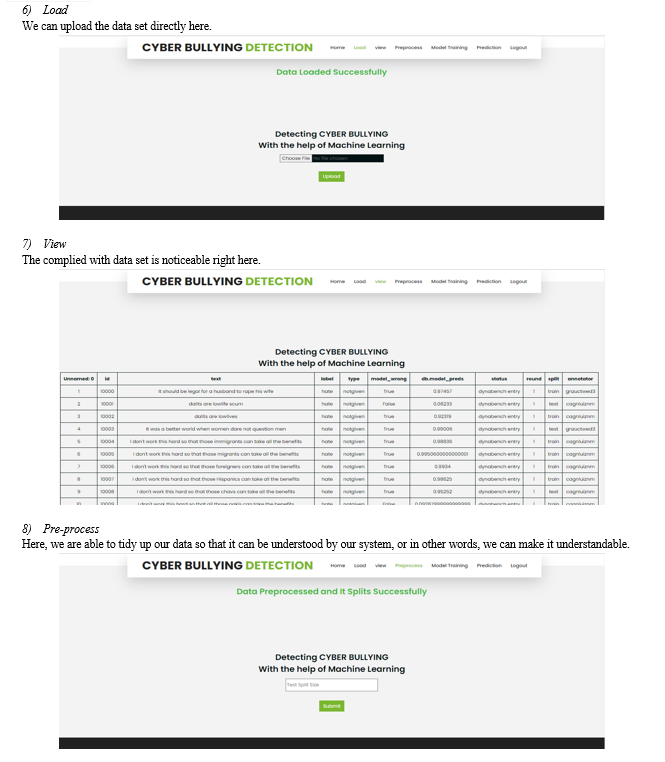
B. Performance Evaluation Metrics for Algorithm Comparison
When it comes to machine learning algorithms, there are several popular options to consider. In this comparison, we will examine the Random Forest algorithm and its superiority over LSTM, CNN, Logistic Regression, and Naive Bayes algorithms. Through its unique characteristics and exceptional performance, Random Forest emerges as the best choice for a wide range of tasks.
To make reliable forecasts, the Random Forest ensemble learning approach pools the results of several individual decision trees. It works by generating many decision trees during training and then averaging their findings to get accurate conclusions. When compared to other algorithms, this method has several benefits. To begin, Random Forest performs very well with both numerical and categorical data. Its flexibility in handling features of varying sorts and sizes makes it useful in a wide range of practical contexts. Contrarily, LSTM and CNN algorithms are designed particularly for sequence and visual data, limiting their usefulness to many domains. Moreover, Random Forest is known for Its willingness to manage datasets with plenty of characteristics and a high dimension. This algorithm automatically selects the most informative features during the tree construction process, effectively reducing the dimensionality and preventing over fitting. On the other hand, Logistic Regression and Naive Bayes algorithms may struggle when faced with datasets containing numerous variables, as they make assumptions about feature independence or linearity.
Random Forest also excels in handling missing values and outliers within the dataset. It can robustly handle noisy and incomplete data without requiring extensive data preprocessing. In contrast, LSTM, CNN, Logistic Regression, and Naive Bayes algorithms might need additional steps such as imputation or outlier removal, which can introduce complexities and potentially impact the quality of the results. Furthermore, Random Forest offers excellent interpretability and feature importance ranking. It can provide insights into which features the model's performance the most profound impact predictions. This interpretability is crucial in many fields were understanding the underlying factors driving the results is essential. In contrast, LSTM and CNN are thought to be "black-box" models, making it difficult to understand how they make decisions.
Lastly, Random Forest exhibits remarkable robustness against over fitting. The ensemble nature of the algorithm, along with the randomness introduced during tree construction, helps mitigate the risk of over fitting and provides more generalizable models. LSTM, CNN, Logistic Regression, and Naive Bayes algorithms might be more susceptible to over fitting, especially when dealing with complex and noisy datasets. The Random Forest algorithm stands out as the best choice among LSTM, CNN, Logistic Regression, and Naive Bayes algorithms for several reasons. Its versatility, ability to handle high-dimensional data, robustness against missing values and outliers, interpretability, and resistance to over fitting make it a powerful tool in various machine learning applications. Whether dealing with structured or unstructured data, Random Forest consistently delivers accurate and reliable results, making it the algorithm of choice for many data scientists and practitioners.
Conclusion
A. Conclusion We implemented word classification techniques to try to uncover cyberbullying in the data from twitter. Even Although we as a species have used a variety of For the dataset that we were experimenting with, Long Short-Term Memory (LSTM) and Convolutional Neural Network (CNN) are two examples of text-based classification algorithms that may be utilised in the future; other machine learning models or approaches, such as Logistic Regression and even Natural Language Processing (NLP), may also be used. B. Future Scope Many potential changes or enhancements need to be considered for the next phase of development. For this project, we\'ve decided to employ the ID3 and Naive Bayes classifiers, two data mining classifiers. The Bayesian network classifier, the C4.5 classifier, and the classifier from neural networks are further classifiers. Such classifiers could be applied They weren\'t covered in this study, accordingly in the future individuals will need to supply more information for comparison.
References
[1] Badjatiya, P., Gupta, S., Gupta, M., Varma, V.: Deep learning for hate speech detection in tweets. In: Proceedings of the 26th International Conference on World Wide Web Companion. pp. 759–760 (2017) [2] Dinakar, K., Reichart, R., Lieberman, H.: Modeling the detection of textual cyberbullying. In: fifth international AAAI conference on weblogs and social media (2011) [3] Djuric, N., Zhou, J., Morris, R., Grbovic, M., Radosavljevic, V., Bhamidipati, N.: Hate speech detection with comment embeddings. In: Proceedings of the 24th international conference on world wide web. pp. 29–30 (2015) [4] Duchi, J., Hazan, E., Singer, Y.: Adaptive subgradient methods for online learning and stochastic optimization. Journal of machine learning research 12(7) (2011) [5] Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural computation 9(8), 1735–1780 (1997) [6] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014) [7] Nobata, C., Tetreault, J., Thomas, A., Mehdad, Y., Chang, Y.: Abusive language detection in online user content. In: Proceedings of the 25th international conference on world wide web. pp. 145–153 (2016) [8] Patchin, J.W., Hinduja, S.: Bullies move beyond the schoolyard: A preliminary look at cyberbullying. Youth violence and juvenile justice 4(2), 148–169 (2006) [9] Schuster, M., Paliwal, K.K.: Bidirectional recurrent neural networks. IEEE transactions on Signal Processing 45(11), 2673–2681 (1997) [10] Servance, R.L.: Cyberbullying, cyber-harassment, and the conflict between schools and the first amendment. Wis. L. Rev. p. 1213 (2003) [11] Tieleman, T., Hinton, G.: Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning 4(2), 26–31 (2012)
Copyright
Copyright © 2023 Patnana Sayesu. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET55214
Publish Date : 2023-08-07
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online