

Ijraset Journal For Research in Applied Science and Engineering Technology
Veracity Assessment of Multimedia Facebook Posts for Infodemic Symptom Detection using Bi-modal Unsupervised Machine Learning Approach
Authors: Taiwo Olapeju Olaleye, Peter Ugege, Ayobami Ademoroti, Taiwo Olomola, Oluwatobi Ilugbo , Oluwayemisi Shofoluwe
DOI Link: https://doi.org/10.22214/ijraset.2021.39406
Certificate: View Certificate
Abstract
Ascertaining the truthfulness and trustworthiness of information posted on social media has been challenging with the proliferation of unsubstantiated, misleading, and inciting news, with different intents by purveyors. Unlike the traditional media with some level of regulations, user-generated posts on social networks does not pass through censorships in order to establish the truism of news items hence the need to be cautious of posted information on the networks. The lingering issue of recent suspension of Twitter microblogging site by the Nigerian government and the consequent decision to regulate social network operations in the country similarly centers on the subject of social media dependability for legitimate social engagements by millions of savvy Nigerian users. Whereas existing models in literature have proposed state-of-the-arts, this study seeks to improve on obtainable studies with a bi-modal machine learning methodology that indicate symptoms of infodemic social media posts. Using a multimedia facebook corpus, an unsupervised natural language processor, Inception v3 model, coupled with a hierarchical clustering network, is deployed for the duo of image and text sentiment analytics. Experimental result uniquely identified infodemic tendencies in facebook text-corpus and efficiently differentiates image-corpus into respective clusters through the Euclidian distance metrics. The most infodemic post returned a -0.9719 compound score while the most positive post returns 0.9488. Veracity assessment of polarized opinions expressed in negative clusters reveals that provocative, derogatory, obnoxious, etc. indicate propensity for infodemic tendencies.
Introduction
I. INTRODUCTION
Social media is unarguably the official voice of the global village where both digital natives and immigrants freely express opinions on wide range of issues relating to international, continental, national or sub-national concerns. It is commonplace for
government information managers and citizens alike to spontaneously take to social media to report breaking news or contribute to an ongoing discussion but with a slip side to this commendable expanded access (Garcia-Pueyo, et al., 2021). Unlike the
regulated traditional media, user-generated posts on social media are without censorship nor regulations, in most countries, which accounts for the proliferation of fake news (Qi, Cao, Yang, Guo, & Li, 2019). A social media post is fake if its content is deliberately and verifiably false and could deceive or mislead readers while a fake image-news item is only attached to a fake social media post (Qi, Cao, Yang, Guo, & Li, 2019). The global posture of fake news epidemic notwithstanding, its prevalence is often drawn by local issues and circumstantial national situations. Hence, there is dire need to acknowledge the locality of the global problem by examining fake news proliferation at the micro-level (Apuke & Omar, 2020). Fake news about a pandemic, notwithstanding the intent of purveyors, is regarded as a more deadly pandemic in itself hence, fake news is regarded as infodemic (Olaleye T. , Arogundade, Abayomi-Alli, & Adesemowo, 2021) to reiterate its dangerous dimension and its implication on unsuspecting readers. The 2021 internet user penetration in Nigeria is put at 47.9% of its population, a figure that is expected to rise to 64.9% by 2025 (Varrella, 2021), with Facebook having 86.2% utilization preference. Facebook users often deploy multimedia approach including images alongside texts in their user-generated posts to convey intents. Images are known to depict profound impressions which are easily understandable by readers (Daniela, Birlutiu, & P., 2020). Actually, the contextual polarity of a Facebook post could be efficiently inferred from the text and visual content through sentiment analysis (Lynch, et al., 2020).
In this opinion mining study therefore, an integrity check is computed on emotions expressed in text-posts as well as on the pictorial representations encapsulated in its accompanying image in order to identify infodemic thresholds for each posted document, which is an improvement on recent state-of-the-art, majority of which only deploys either text or image in their sentiment analysis of Facebook posts and mostly deploys old public benchmarks for single event analysis. The rest of this study is organized in the following ways: Section II discusses related works, while Section III presents the methodology for the severity clustering. Section IV discusses the result while conclusion is presented in Section V.
II. REVIEW OF RELATED STUDIES
The work of (Tacchini, Ballarin, Vedova, Moret, & Alfaro, 2017) is a binary classification modelling of Facebook posts with logistic regression on a training set of 15,500 to identify hoaxes. In Ref. (Gupta, Lamba, Kumaraguru, & Joshi, 2017), the role of twitter in spreading fake images during 2012 Hurricane Sandy was studied mining 10,350 unique corpus through characterization analysis to unravel the temporal, social standing and influence strategy of fake image purveyors. In (Choras, Gielczyk, Demestichas, Puchalski, & Kozik, 2018), a pattern identification solution for forged image detection study is conducted with skewed attention on the accompanying image of a post with the intent that if a posted image is forged, the corresponding text may not pass integrity check. In (Mittal, Sharma, & Joshi, 2018), a deep learning neural network-based review is conducted for sentiment analysis of social media post using different deep learning techniques including DNN, R-CNN, Fast R-CNN, and CNN, while (Xu, Li, Huang, Li, & S.Yu, 2020) proposes a multi-modal learning approach to capture relations between image and text through heterogeneous relational model with incorporation of rich social information. In Ref. (Qi, Cao, Yang, Guo, & Li, 2019), a multi-domain visual neural network model to fuse the pictorial information of frequency and pixel domain for fake news detection is presented. Proposed CNN-based network automatically captures the multifaceted patterns in fake-news images in the frequency domain while applying a multi-branch CNN-RNN model to visual attributes from different semantic levels in the pixels outperforming existing models with at least a 9.2% accuracy while improving multi-modal detection accuracy of fake news to the tune of 5.2%. The significance of user profile for fake news detection is the thrust of the Ref. (Shu, Zhou, Wang, Zafarani, & Liu, 2019) by investigating research questions that borders on the nature of users with higher propensity of sharing fake news, the characteristic features of fake and real news purveyors, and the possibility of deploying user profile features in detecting fake news. Ref. (Marra, Gragnaniello, Cozzolino, & Verdoliva, 2018) presents a detection framework to identify generative adversarial network-based fake images on social media networks through the data analytics of 36302 image corpus by conventional and deep learning detectors while Ref. (Zeng, Zhang, & Ma, 2020) studied the semantic correlation between text and images for fake news detection in epidemic emergencies by learning the image representation through pre-trained VGG model hence enhancing the study of text representation through hierarchical thoughtfulness apparatus. The work of (Jiang, Song, Scarton, Aker, & Bontcheva, 2021) introduced a fine-grained marked COVID-19 fake tweet corpus for the classification pipeline aimed at detecting correlation of infodemic spread with other behaviours of purveyors. In Ref. (Santia & Williams, 2018), an annotated dataset is built using collections of facebook posts in September 2016 for veracity by BuzzFeed away from the usual binary classification to mostly true, mostly false, mixture of true and false, and no factual captured through Graph API. The veracity valuation of online data is the thrust of (Lozano & Vlassov, 2020) asserting text analytics as the most preferred approach towards veracity assessment in supervised learning.
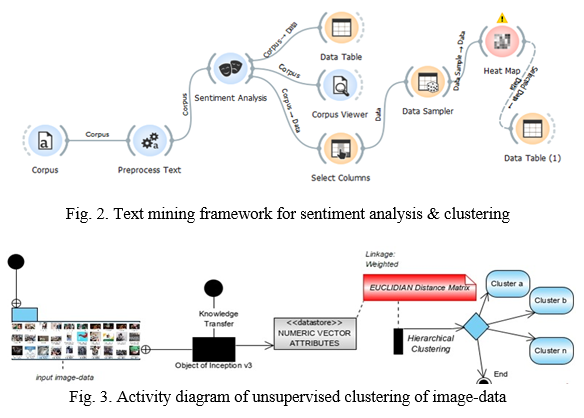
III. COMPUTATIONAL FRAMEWORK OF RESEARCH METHODOLOGY
The proposed dual-technic for veracity assessment of Facebook multimedia posts towards determining the infodemic symptoms of the posts is as captured on the activity diagram in Fig. 1. Data was acquired over various threads and hashtags between March 2020 and June 2021 covering three topical national events at different times as recommended in (Huynh, Le-Tien, V.Huynh, & C.Nguyen, 2015). Events surrounding the COVID-19 lockdown, COVID-19 vaccinations and the highly controversial #EndSARS are the subjects of the posts. Data extracted consist of 91823 text corpus and 631 feature image-pair as sampled on Table 1. The highly unstructured data is preprocessed for conversion to lowercase, filtering of stop words, lemmatization, and tokenization via Regexp etc. Text analytics follows immediately through the VADER-based sentiment analysis, which defines polarity, to distinguish text posts into states of either Positivity, Neutrality & Negativity sentiments. The three sentimental states ultimately determines the compound score for each textual expression, which determines the extent of being infodemic, similar to (Hota, Sharma, & Verma, 2021). In its computations, the word ‘w' is assigned numeric value 1, 0, or -1 for positive, neutral or negative emotion. Therefore, polarity of a text ‘T’ is:


using the sum of valence scores (x) of each word in the lexicon, which is rejigged with the rules and normalized between -1 (high infodemic symptoms) and +1 of no infodemic symptoms and α is normalization constant with default value 15. Infodemic symptoms is then computed as:
nill or low infodemic symptoms when: compound score >= 0.05
un-deterministic infodemic status when compound score > -0.05 and < 0.05
while high infodemic symptoms suffixes when compound score <= -0.05
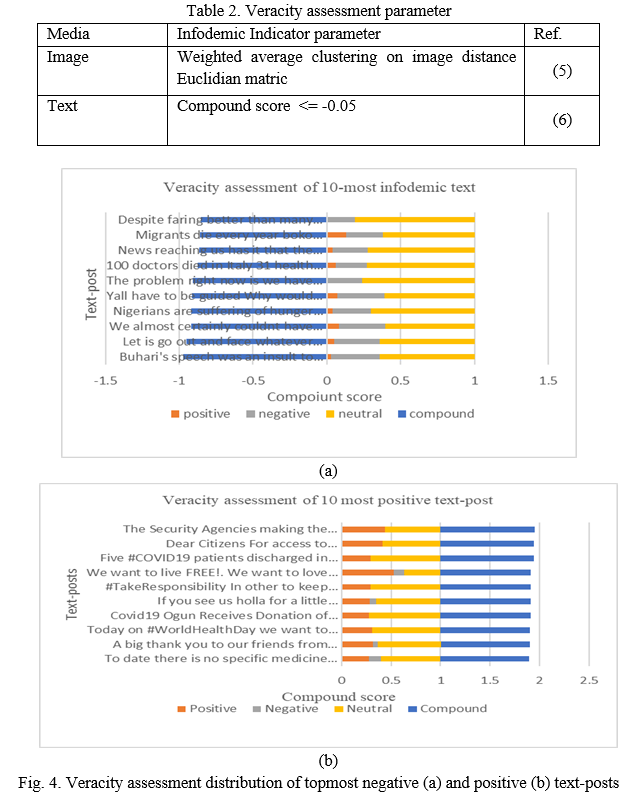
The resulting positive, negative and neutral granularity is passed through a data sampler (to logically group the textual posts into clusters) after columns have been properly set as presented on the framework in Fig. 2. A 10% fixed proportion of data is set for the sampling towards clustering of the output with replicable deterministic sampling prior to veracity assessment.
Image analytics follows on the pictures accompanying each Facebook post with Inception v3 & Hierarchical Clustering.
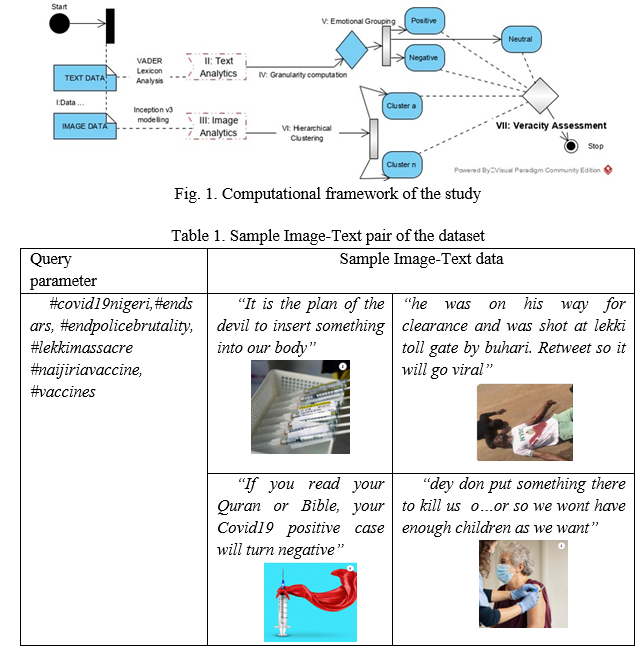
Extraction of numeric vectors via image embedding is implemented and as illustrated in
Fig. 3, a deep learner Inception v3 predefined convolutional neural network containing 28 layers is applied for attribute extraction through transfer learning. Hence, the resulting numeric vector attributes is subjected to hierarchical clustering. Prior to the clustering, a distance matrix is computed which shows distance between objects represented in the numeric vector image-corpus. Distances between rows is adopted while the distance metric adopted is Euclidian and is derived by

From where the distance between clusters are derived. However, a weighted average linkage measure criterion, which determines the distance between sets of observed similarity, a function of the pairwise distances between the observations, is adopted and derived by

Which leads to the hierarchical clustering. Each observations from the corpus is treated as separate cluster then the algorithm repeatedly identify two clusters with close proximity, and merges two most similar clusters. The iterative process continues until all the clusters are merged together.
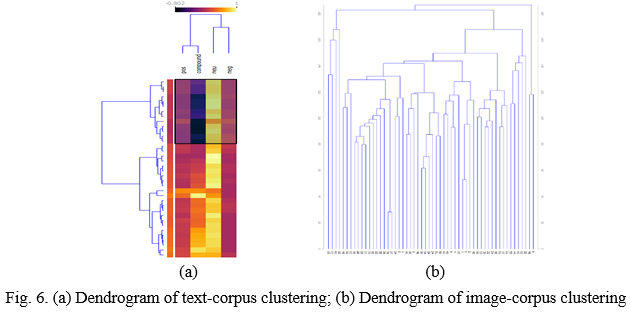
The veracity assessment of infodemic tendencies expressed in the Facebook posts, as observed from the symptoms identified from the image-text corpus through sentiment analysis, is decided as described on Table 2. This is established on the indicators as expressed by similar behaviors of the Facebook posts proven by (Lozano & Vlassov, 2020).
IV. RESULT AND DISCUSSION
The continuous polarity annotation adopted by VADER with respect to the indicator parameter on the third row of Table 2 computed the emotional status of each text-data which determines their infodemic tendency through the compound score which is methodical by ranking between the range of +1.0 to -1.0. Out of the entire text corpus, 35.744% shows symptoms of infodemic with compound score ranging from -0.0516 and -0.9719, occasioned by the veracity of negative emotions communicated in the text-post. A 40.21% of the corpus are expressed with positive sentiments between 0,0516 and 0.9488 while 24.04% (between -0.0258 and 0.037) were neutral in their posts. The resulting computations are clustered through data sampling as indicated on Fig. 2. By implication, the 10-most infodemic text-posts in the corpus with highest symptoms of infodemic tendencies is presented in Fig. 4 (a), part of which is highlighted on Fig. 6 (a) heat map showing the veracity distribution of the likelihood of their fakeness, while similar 10-most positive sentiments is captured in the (b) part of Fig. 4.
A. Similarity Index Assessment of Image-Corpus
The feature vectors computed through image embedding, upon which the clustering algorithm is applied through the Euclidian distance metrics, produced a dendrogram upon the hierarchical clustering, as shown in Fig. 6 (b). A closer look at six sample clusters with their corresponding image grids are as presented earlier in Fig. 5. Cluster (a) with a 10*9 matrix grid, is representative of the three events being addressed by the Facebook users whose posts were captured. On the grid, images are clustered with obvious similarities in their infographic, colorization, genetic make-up, elements captured etc. Observation shows grid (b) 5*5 matrix cluster is composed of blood-stained images supposedly attached to text-posts discussing the controversial #LekkiMassacre while the scattered grid (c) cluster, with large white space surface area between rows and columns, is made up of synthetic graphics obviously created with photo editors. Close observation shows graphics presented on the first row of the grid has traces of the green-white-green Nigerian flag and the pair on the other row has deep red-colour of a scarf and cap respectively. Grids (d)-(f) of 6*5, 1-row, and 7*7 matrixes of close proximity on the image-input cluster are mainly composed of images over the #EndSars protests across the country. The grids are sub-clusters of a bigger branch on the dendrogram.

A veracity correlation assessment of image-text pair of the most negative and positive text-post as presented on Table 3 shows the emotional state of the posts with respect to the their compound sentiment analysis score alongside their image-post. While image-data of the most positive post is clustered with similar images of protesters on the road, image-post of the most negative post in the corpus is clustered among portraits represented in the image-corpus. Image clusters shows deep similarities though the context upon which they are used might be different and spread across the three peculiar polarities. Experimental result shows that though posted images may not be directly connected to text posts, users often use images that describes their intents. Therefore, while images are clustered with obvious similarities with their neighborhood clusters, the context upon which they are used in their respective posts may differ. It is noteworthy that the post with most negative emotion as presented on Table 3 actually is credited to spokesperson of the opposition political party in Nigeria and while the trustworthiness and or the truism of the opined assertions made therein remains a subject of debate, proposed model in this study appropriately clustered the post probably due to the choice of words with respect to the dictionary-of-known-words operational with VADER-based lexicon model. By implication, derogatory, offensive and similar words used in posts, that could incite negative emotions, are most likely to be infodemic.

V. ACKNOWLEDGMENTS
Authors appreciate the efforts of the reviewers toward the final and better outcome of this chapter.
Conclusion
In this study, we investigated a proposed unsupervised machine learning bi-model experimented with social media posts discussing three topical issues of national interest to Nigeria. Experimental result shows 24.04% of posts are of neutral infodemic symptoms while 40.21% expressed positive sentiments in their posts. A 35.744% of the entire Facebook-corpus exhibits symptoms of infodemic tendencies with respect to the computations of the compound sentiment score. The image-posts accompanying each facebook posts were efficiently clustered with results showing close similarities on the image grid presented in a row*column matrix. The most infodemic post returned a -0.9719 compound score with the most positive post returning a 0.9488 compound score value. Facebook posts discussing the lockdown and EndSARS returned majority of documents clustered as negative while COVID-19 related posts mostly cluster along neutral sentiments. Future study will factor-in the profile description attribute of Facebook users in the corpus while API will be adopted in the acquisition of data to enable bigger corpus.
References
[1] Apuke, O. D., & Omar, B. (2020). Fake News Proliferation in Nigeria: Consequences, Motivations, and Prevention through Awareness Strategies . Humanities & Social Sciences Reviews, 318-327. [2] Choras, M., Gielczyk, A., Demestichas, K., Puchalski, D., & Kozik, R. (2018). Pattern Recognition Solutions for Fake News Detection. CISIM 2018 (pp. 130–139). Switzerland: Springer Nature. [3] Daniela, O., Birlutiu, A., & P., D. L. (2020). Towards Mapping Images to Text Using Deep-Learning Architectures. Mathematics, 8(1606), 1-18. [4] Dong, N., Zhao, L., Wu, C., & Chang, J. (2020). Inception v3 based cervical cell classification combined with artificially extracted features. Applied Soft Computing Journal, 93(106311), 1-8. [5] Garcia-Pueyo, L., Bhaskar, A., Kumar, P. S., Tsaparas, P., Garimella, K., Sun, Y., & Bonchi, F. (2021). MISINFO 2021: Workshop on Misinformation Integrity in Social Networks. 30th ACM The Web Conference. Ljubljana: ACM. [6] Gupta, A., Lamba, H., Kumaraguru, P., & Joshi, A. (2017). Faking Sandy: Characterizing and Identifying Fake Images on Twitter during Hurricane Sandy. WWW 2013 Companion. Rio de Janeiro: ACM. [7] Hota, H., Sharma, D. K., & Verma, N. (2021). Lexicon-based sentiment analysis using Twitter data: a case of COVID-19 outbreak in India and abroad. In U. Kose, D. Gupta, V. H. Albuquerque, & A. Khanna, Data Science for COVID-19 (pp. 275-293). London: Mara Conner. [8] Jiang, Y., Song, X., Scarton, C., Aker, A., & Bontcheva, K. (2021). Categorising Fine-to-Coarse Grained Misinformation: An Empirical Study of the COVID-19 Infodemic. arXivpreprint arXiv:2106.11702.2021, 1-16. [9] K.Huynh, T., Le-Tien, T., V.Huynh, K., & C.Nguyen, S. (2015). A Survey on Image Forgery Detection Techniques, Research, Innovation, and Vision for Future (RIVF). 2015 IEEE RIVF International Conference on Computing & Communication Technologies. IEEE. [10] Lozano, M. G., & Vlassov, V. (2020). Veracity assessment of online data. Decision Support Systems . [11] Lynch, C., O’Leary, C., Smith, G., Bain, R., Kehoe, J., Vakaloudis, A., & Linger, R. (2020). A review of open-source machine learning algorithms for twitter text sentiment analysis and image classification. International Joint Conference on Neural Networks (IJCNN) (pp. 1-9). IEEE. [12] M, N., S, R. S., & B, U. M. (2019). Fruit Recognition and Grade of Disease Detection using Inception V3 Model. Third International Conference on Electronics Communication and Aerospace Technology [ICECA 2019]. [13] Marra, F., Gragnaniello, D., Cozzolino, D., & Verdoliva, L. (2018). Detection of GAN-generated Fake Images over Social Networks. 2018 IEEE Conference on Multimedia Information Processing and Retrieval (pp. 384-389). IEEE. [14] Mittal, N., Sharma, D., & Joshi, M. L. (2018). Image Sentiment Analysis using Deep Learning. 2018 IEEE/WIC/ACM International Conference on Web Intelligence (WI). IEEE. [15] Olaleye, T., Arogundade, O., Abayomi-Alli, A., & Adesemowo, K. (2021). An Ensemble Predictive Analytics of COVID-19 Infodemic Tweets using Bag of Words. Data Science for COVID-19, 365-380. [16] Qi, P., Cao, J., Yang, T., Guo, J., & Li, J. (2019). Exploiting Multi-domain Visual Information for Fake News Detection . 2019 IEEE International Conference on Data Mining (ICDM) . [17] Santia, G. C., & Williams, J. R. (2018). BuzzFace: A News Veracity Dataset with Facebook User Commentary and Egos. Proceedings of the Twelfth International AAAI Conference on Web and Social Media (ICWSM 2018), (pp. 531-540). [18] Shu, K., Zhou, X., Wang, S., Zafarani, R., & Liu, H. (2019). The Role of User Profiles for Fake News Detection. 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. Vancouver: ACM. [19] Tacchini, E., Ballarin, G., Vedova, M. L., Moret, S., & Alfaro, L. d. (2017). Some Like it Hoax:Automated Fake News Detection in Social Networks. Santa Cruz: School of Engineering, University of California. [20] Varrella, S. (2021, March 23). statistics/1176101/leading-social-media-platforms-nigeria. Retrieved from www.statista.com: https://www.statista.com/statistics/1176101/leading-social-media-platforms-nigeria/ [21] Xu, J., Li, Z., Huang, F., Li, C., & S.Yu, P. (2020). Social Image Sentiment Analysis by Exploiting Multimodal Content and Heterogeneous Relations. IEEE Transactions on Industrial Informatics. [22] Zeng, J., Zhang, Y., & Ma, X. (2020). Fake news detection for epidemic emergencies via deep correlations between text and images. Sustainable Cities and Society, 1-32.
Copyright
Copyright © 2022 Taiwo Olapeju Olaleye, Peter Ugege, Ayobami Ademoroti, Taiwo Olomola, Oluwatobi Ilugbo , Oluwayemisi Shofoluwe. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET39406
Publish Date : 2021-12-13
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online