

Ijraset Journal For Research in Applied Science and Engineering Technology
Vision and Voice Based Hand Gesture Recognition
Authors: S. Abdul Raheem, A. Shiva Sai, B. Keerthana, Asst. Prof. Mrs. A. Amulya
DOI Link: https://doi.org/10.22214/ijraset.2023.53731
Certificate: View Certificate
Abstract
The development of sign language over time has been astounding. It\'s unfortunate that this language has some unpleasant side effects. Not everyone can understand spoken sign language when using sign language among a mute or deaf person. For deaf-dumb people, hand gestures and sign language are important forms of communication. Communication is difficult without an interpreter, hence it is necessary to translate sign language so that it is understandable to the general public. The goal is to increase the participation of the deaf and the mute in communication. In order to incorporate colour, depth, and trajectory information to increase performance, the CNN is fed numerous channels of video streams that include body joint locations in addition to depth cues and colour information. We demonstrate how the proposed model outperforms conventional approaches based on hand-crafted features by testing it on a real dataset gathered using Microsoft Kinect.
Introduction
I. INTRODUCTION
Today's technology has made life quicker and more automated, so we don't need as many complicated methods to do tasks. But even in this automated environment, the disabled are not benefiting all that much. The main reason for this is that their communication style differs from that of the general population, and advances in technology have not paid much attention to those with specific disabilities.
Without gestures or sign language, Deaf and Dumb individuals always struggle to communicate with regular people. A gesture is a form of informational nonverbal communication.
To preserve a line of communication with the other individuals, the Hand Gesture Recognition system localises and tracks the hand gestures of the dumb and deaf persons. The purpose of this programme is to assist dumb and deaf persons in communicating with others by visualising and tracking their hand motions.
II. RELATED WORK
- O. Mercanoglu Sincan and H. Y. Keles, "Using Motion History Images With 3D Convolutional Networks in Isolated Sign Language Recognition," in IEEE Access, 2022
The method put out in this research creates a model for sign language recognition using simply RGB data without specifically segmenting hands or face regions. Thus, the model creates an RGB-MHI image that reduces the entire movie to a single frame and offers an RGB-MHI model that makes use of these single images to learn a representation of relevant spatial and motion patterns. Two tactics are offered in this regard: The first method specifically segmented the hands and face; the model suggested here concentrates on motion patterns with RGB-MHI pictures. Just before the prediction, the second method involves integrating RGB and RGB-MHI features.
2. Y. Wang, Y. Shu, X. Jia, M. Zhou, L. Xie and L. Guo, "Multifeature Fusion-Based Hand Gesture Sensing and Recognition System," in IEEE Geoscience and Remote Sensing Letters, vol. 19, 2022
This research proposes a CMFF-HGR+WMA system for sensing and recognizing gestures with the hands. In order to generate the pertinent feature maps, the hand gesture's range, Doppler, and angle information were measured using FFT and the MUSIC method. To avoid over-fitting, the dataset was expanded and the WMA approach was applied.
Then, by combining skip connections with residual learning, the CMFFHGR was developed to extract the unique properties of the 3-D hand gesture maps. Extensive experiments were done to confirm this suggested strategy's effectiveness.
III. METHODOLOGY
A. Proposed Architecture
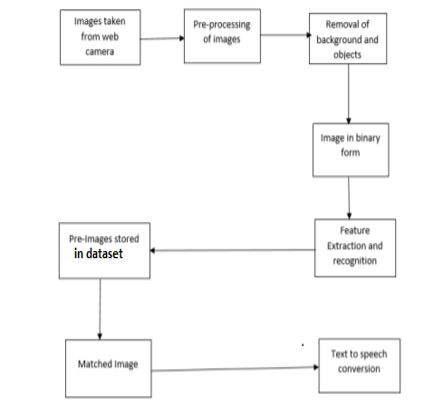
B. Proposed System
The methodology used in this project is entirely based on the hand gesture's form properties. Since skin texture and colour are image-based variables that vary greatly depending on lighting and other factors, it does not take any other methods of hand gesture identification into account. The algorithm transforms the Gestures video into simple English words and creates sentences using each word. In other words, this system uses a webcam to capture the motion, which is then processed, transformed to text, and last, translated into speech. The matching results are produced using the CNN method used in the video processing module. Depending on the accurate match, the Sign Writing Image File is retrieved and saved in a certain folder.
C. Proposed Algorithm
Artificial neural networks (ANNs) of the type convolutional neural networks (CNN) are frequently used in deep learning to process visual input. CNNs, often called as Shift Invariant Artificial Neural Networks (SIANN), are built using shared-weight convolution kernels or filters that slide along input features and generate feature maps that are translation-equivariant outputs. Contrary to popular belief, most convolutional neural networks do not translate invariantly, even though they typically perform a down sampling operation on the input. They are useful for a range of activities, including video and image recognition, recommender systems, image classification and segmentation, image analysis for medical purposes, brain-computer interfaces, natural language processing, and financial data time series. Multilayered perceptrons are the basis for CNNs, which are regularized versions . CNNs take a different tack when it comes to regularization since they take advantage of the hierarchical nature of the data to produce patterns that get more complicated as they get smaller and are imprinted in their filters. So, on a connection and complexity scale, CNNs are at the bottom.


Conclusion
In order to communicate with the deaf and dumb, we designed a synchronised user-friendly application that can translate hand motions into sign language using CNN and a pre-trained model. The strategy used in this project is entirely based on the hand gestures. Due to the significant variability of these image-based attributes under various lighting conditions and other effects, it does not take into account any other methods of hand motion identification such as skin texture or colour. The algorithm transforms the Gestures video into simple English words and creates sentences using each word. In other words, this system uses a webcam to capture the motion, which is then processed, transformed to text, and last, translated into speech. The matching results are produced by the CNN method used in the video processing module. The Sign Writing Image File is retrieved and saved in a particular folder based on the accuracy of the match.
References
[1] O. Mercanoglu Sincan and H. Y. Keles, \"Using Motion History Images With 3D Convolutional Networks in Isolated Sign Language Recognition,\" in IEEE Access, vol. 10, pp. 18608-18618, 2022, doi: 10.1109/ACCESS.2022.3151362. [2] C. Zhu, J. Yang, Z. Shao and C. Liu, \"Vision Based Hand Gesture Recognition Using 3D Shape Context,\" in IEEE/CAA Journal of Automatica Sinica, vol. 8, no. 9, pp. 1600-1613, September 2021, doi: 10.1109/JAS.2019.1911534 [3] Y. Wang, Y. Shu, X. Jia, M. Zhou, L. Xie and L. Guo, \"Multifeature Fusion-Based Hand Gesture Sensing and Recognition System,\" in IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1-5, 2022, Art no. 3507005, doi: 10.1109/LGRS.2021.3086136.
Copyright
Copyright © 2023 S. Abdul Raheem, A. Shiva Sai, B. Keerthana, Asst. Prof. Mrs. A. Amulya. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET53731
Publish Date : 2023-06-04
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online