

Ijraset Journal For Research in Applied Science and Engineering Technology
Voice Coding using ML
Authors: Chinmay Paradkar, Aman Singh, Suneel Yadav
DOI Link: https://doi.org/10.22214/ijraset.2022.41939
Certificate: View Certificate
Abstract
In this digital era there are various digitization is happening like the AI is deploying so fast, various automations are happening and taking place of human and reducing the efforts of human. And all this things are happening because of programmers/developers they are doing a very hard work for the development of technology. As effect of this this work many developers/programmers are facing various physical / mental disorders like stress, carpel tunnel syndrome and more problems. So we are developing a system which will reduce their injuries or problems like this by creating solution i.e. they have to just speak they want code the system will take it and create proper code. In today’s world, many artificial intelligence applications developed using programming languages like Python, R and so on. Each language comes with its own programming structure and syntactical forms. Programmers are broadly classified into three categories namely, novice users, knowledge intermittent and expert one. For novice users, it is always a challenge to write a code without typographic errors though users know theoretical knowledge of Programming language, its structure and syntax as well as logic of program. Therefore, this paper explores use of voice recognition technique in the field of programming, specifically for writing program with Python programming language. In experimental analysis, it found helpful for new Python programmers and provide new learning curve for programmers wherein beginner can experience hassle free program writing. This paper adds new way of creating interest in beginners for judging their coding paradigm understanding and explore one of the area for user experience field for better programming Integrated Development Environment Development (IDE). Keywords: Artificial Intelligence, Learning, User Experience, Voice Recognition.
Introduction
I. INTRODUCTION
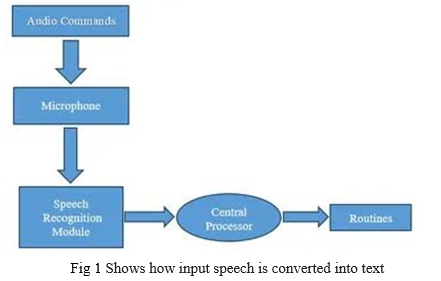
Programming involves human efforts, hardware and due to manual typing through keyboard, there are many chances to meet an error while typing. As programming is important for students and innovation, as manual typing is time, consuming there is a need for an advanced system, which would reduce programmer’s effort and promote smart work. The system, which we are going to develop, is easier than this manual typing of code. We are going to recognize the voice of user through the microphone and those keywords will be matched with the stored keywords if they are matched then that will be displayed on editor and that is the code or programme in a specific language, which can be further compiled and executed through the voice instructions of user. In the first phase of proposed system, we made use database for the keywords comparison and further in the second phase, we will be going from machine learning concept in which the next keyword will be recognized by using the previous keyword by using the machine learning algorithm and will be printed on the editor will be compiled and executed through user voice instructions. Existing systems like Google assistant recognizes the voice and will perform the Operate according to the voice instructions, but in our system we are developing.
The same approach for programming purpose user will able to program or code Through voice without using the keyboard and will able to compile and execute The code through voice instructions of user. In this paper we chosen Python as programming language because of following reasons: Case Sensitivity, Strongly Typed, Object-Oriented, Dynamic one.
A. What is Voice Based Coding?
An approach to developing software using voice instead of a keyboard and mouse to write code. Through voice-coding platforms, programmers utter commands to manipulate code and create custom commands that cater to and automate their workflows .
B. Why Voice Coding?
Programming involves human efforts, hardware and due to manual typing through keyboard, there are many chances to meet an error while typing. As programming is important for students and innovation, as manual typing is time, consuming there is a need for an advanced system, which would reduce programmer’s effort and promote smart work
C. Previous Work
Previously there are some programs created by people but the difference is that it works in run evaluate environment (i.e. on command prompt). And also some plugins are also developed but they just take input from user as the required syntax. We are developing a solution which will take an instruction from user but there’s a no need to give it with syntax
D. Motivation
The system, which we are going to develop, is easier than this manual typing of code. There is a open source speech recognition names Dragonfly having 15 versions. At the start very few People were using it but in the last two years there's been a drastic change and a number of pull requests and updates are happening from the world and the reason behind this is the term automation. As the researchers and developers working on automation they found it very useful. As it gives a freedom to create our own grammar. By using this we are creating a total voice coding platform
II. AIM , SCOPE AND OBJECTIVES
A. Aim
Aim of this system is to make development of Python program easy and interesting and allow anyone to develop a program using voice commands with minimal programming knowledge.
???????B. Scope
The goal of this system is to provide an easy platform for the users to develop a Python program easily, to create more interest of user in programming, to reduce the use of resources, and minimize the human efforts and reduce the time.
??????????????C. Objectives
Based on findings and requirement, Following objectives are set for this work.
Proposed System will provide the facility of developing a code through voice instructions. System will be able to save Python the recognized code by voice instructions. System will provide the compile the developed code through voice instructions. System will be able to compare the keywords with database. It will provide the way to get the recognized keywords on the editor. It will provide the facility to execute the developed code through voice instructions.
III. LITERATURE REVIEW
Thiang, et al. (2011) presented speech recognition using Linear Predictive Coding (LPC) and Artificial Neural Network (ANN) for controlling movement of mobile robot. Input signals were sampled directly from the microphone and then the extraction was done by LPC and ANN .
Ms.Vimala.C and Dr.V.Radha (2012) proposed speaker independent isolated speech recognition system for Tamil language. Feature extraction, acoustic model, pronunciation dictionary and language model were implemented using
HMM which produced 88% of accuracy in 2500 words .
Cini Kurian and Kannan Balakrishnan (2012) found development and evaluation of different acoustic models for Malayalam continuous speech recognition. In this paper HMM is used to compare and evaluate the Context Dependent (CD), Context Independent (CI) models and Context Dependent tied (CD tied) models from this CI model 21%. The database consists of 21 speakers including 10 males and 11 females .
Suma Swamy et al. (2013) introduced an efficient speech recognition system which was experimented with Mel Frequency Coefficients (MFCC), Vector Quantization (VQ), HMM which recognize the speech by 98% accuracy. The database consists of five words spoken by 4 speakers at ten times .
Annu Choudhary et al. (2013) proposed an automatic speech recognition system for isolated and connected words of Hindi language by using Hidden Markov Model Toolkit (HTK). Hindi words are used for dataset extracted by MFCC and the recognition system achieved 95% accuracy in isolated words and 90% in connected words .
Preeti Saini et al. (2013) proposed Hindi automatic speech recognition using HTK. Isolated words are used to recognize the speech with 10 states in HMM topology which produced 96.61% .
Md. Akkas Ali et al. (2013) presented automatic speech recognition technique for Bangla words. Feature extraction was done by, Linear Predictive Coding (LPC) and Gaussian Mixture Model (GMM). Totally 100 words recorded in 1000 times which gave 84% accuracy.
Maya Moneykumar, et al. (2014) developed Malayalam word identification for speech recognition system. The proposed work was done with syllable based segmentation using HMM on MFCC for feature extraction .
Jitendra Singh Pokhariya and Dr. Sanjay Mathur (2014) introduced Sanskrit speech recognition using HTK. MFCC and two state of HMM were used for extraction which produces 95.2% to 97.2% accuracy respectively .
In 2014, Geeta Nijhawan et al. developed real time speaker recognition system for Hindi words. Feature extraction done with MFCC using Quantization Linde, Buzo and Gray (VQLBG) algorithm. Voice Activity Detector (VAC) was proposed to remove the silence.
IV. METHODOLOGY
We will be using machine learning concept in which voice will be recognised by using the natural language processing and will be printed on the editor will be compiled and executed through neural network . Existing systems like Google assistant recognizes the voice and will perform the Operate according to the voice instructions, but in our system we are developing The same approach for programming purpose. In this system there’s no need to specify the required syntax the system will automatically identify the required syntax. Let’s consider the below architectural diagram at the very first it will recognize the voice and will take the input from user, i.e. the data will be get collected and then it will be processed and tokenized. after tokening the steaming will takes place in which the words from input which are not required are removed . after this process it will go through the Artificial or deep neural network and will give the desired output as there may be some instructions are not inbuilt so the network is of type self-learning also i.e. of type Reinforcement learning one.
V. PROJECT DESIGN
The system, which is available now days is Google Assistant, but this system recognize the voice and performs an operation. The system, which we are going to develop, will support the specific operation that is developing a computer program through the voice of user, which recognized by the system. Keywords will identified as Key in voice input and will mapped to prepared dictionary database of stored keywords. If it found in this set, it will displayed in user workspace for further processing otherwise an error message will give to user with prompting for correct voice input. After this operation, we will be having the code, which can be further compiled and executed through user’s instructions. The specific words as if compile and run will recognized by the system then system will go for the compilation and execution of code.
The proposed system consist of following modules:
- User Workspace Designing: In this module, we are designing an editor or notepad on which recognized keywords will printed. The printed code can be compiled and executed through user voice instructions.
- Voice Recognition: In this module the proposed system will recognize the voice of user through the microphone and print that keywords on terminal and then on editor.
- Matching Keywords and Print on Editor: The recognized keywords can compared with the keywords, which stored in database and if the comparison returns zero value then the recognized keyword will printed on editor.
- Compile and Execute the Code: The printed code can compiled and executed through the voice instructions of user
VI. RESULT ANALYSIS
A. Implementation Details
The said system implemented using following hardware and software requirements for initial results generation. Hardware Requirements are: Processor –Core i3, Bus speed - 2.5 GT/s DMI, Hard disk - 160 GB, Memory size – 4 GB RAM, Microphone and main interface of system is developed with Software Requirements including PHP, MySQL 5.7.11, JQuery, HTML, CSS and JavaScript.
???????B. Testing Environment
The developed system tested with Window 7.0 and above as well as on Linux 14.4 and above.
??????????????C. Result Analysis
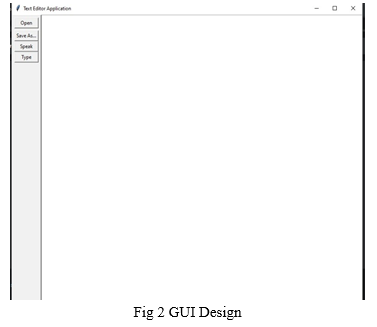
The develop system has given an interface where the user has given option of speak , type , save and open functions. These functions work their own implementation as shown in Fig 3
???????
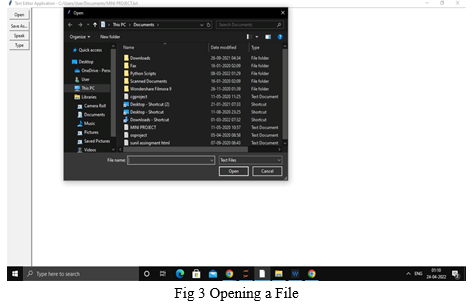
The open function opens the file which needs to be edited or updated as shown in Fig 3 the user is opening a file to perform.
The save function saves the file in the system where later the user can run the file . The type system works as a the user can make changes in the file manually.
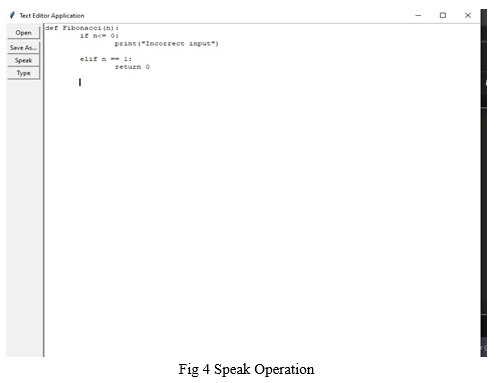
The main function is speak where the user will be able to speak the program and the machine will be printing it as shown in Fig 4 also it would help importing keywords and libraries using shortcuts .
Conclusion
We addressed the problem of user while developing a computer program. Developing a computer program is not an easy task it needs hardware resources which user have to handle. While continuous typing the code there may be possibility of injuries to the fingers of the user. To avoid the problems we are designing a system in which the computer program can developed through the voice. The voice will recognized by the system and that recognized words or word will be compared with the stored keywords in the database and if they are matched then that will be printed on editor and after this again by recognizing the specific keywords the program will be compiled and executed. This system will be easy to use, it reduce human efforts and the use of hardware resources. It would be surely useful for blind as well as novice plus knowledge intermittent users. In future it can also be developed for mouse less use i.e the eye movement can be tracked for cursor.
References
[1] B.H. Juang & Lawrence R. Rabiner Georgia Institute of Technology, Atlanta [2] A study on automatic Speech Recognition. 3 August 2019. Journal of Information Technology Review. 10.6025/jitr/2019/10/3/7785https://www.researchgate.netpublication337155654_A_Study_on_Automatic_Speech_Recognition [3] Jordan J. Bird Elizabeth Wanner Anikó Ekárt Diego R. Faria Optimization of phonetic aware speech recognition through multi-objective evolutionary algorithms 23 July 2018. Journal of Open Source Software. 10.21105/joss.00749. https://joss.theoj.org/papers/10.21105/joss.00749 [4] Jordan J. Bird lizabeth Wanner Anikó Ekárt Diego R. Faria Optimization of phonetic aware speech recognition through multi-objective evolutionary algorithms
Copyright
Copyright © 2022 Chinmay Paradkar, Aman Singh, Suneel Yadav. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET41939
Publish Date : 2022-04-27
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online