

Ijraset Journal For Research in Applied Science and Engineering Technology
Voice To Text Using ASR and HMM
Authors: Mrs. Anuja A. V, Akshatha R, Jayaprakash M
DOI Link: https://doi.org/10.22214/ijraset.2022.44803
Certificate: View Certificate
Abstract
In the modern world, communication technologies have been integrated with the internet. SDSs (speech dialog systems) use voice search technology to answer user’s queries with the information they request. Information normally is stored in a large database, and a query needs to be matched with a field in the database. Research on acoustic modeling focuses on improving robustness to environmental noise, channel conditions, and speaker variation, while research on pronunciation addresses the issue of unseen word sounds and variability in pronunciation.
Introduction
I. INTRODUCTION
Internet is taken into consideration as a prime storehouse of records in today’s world. No single work may be executed without the assist of it. It has even grown to be one of the defects to strategies utilized in verbal exchange. And out of all strategies to be had net browsing and e-mail is one of the maximums not unusual place types of verbal exchange mainly withinside the enterprise world. Information contained at the World Wide Web is inaccessible to many peoples. The net is mainly a visible medium that calls for a keyboard and mouse to navigate. People, who lack motor talents to apply a keyboard and mouse, locate navigation troublesome. Visually impaired people have issues in gaining access to the net. Those who quickly cannot use a conventional net browser, as their eyes or arms are occupied or due to the fact, they're now no longer towards them laptop is at a minimal inconvenienced.

Speech popularity and era technology provide a capability method to those issues through augmenting the abilities of an internet browser. As almost 285 million humans international are envisioned visually impaired it grow to be important to make net centers for verbal exchange usable for them additionally. So, in destiny voice-primarily based totally net e-mail and net looking gadget used to visually impaired humans clean to apply. Therefore, we've got give you this challenge wherein we can be growing a voice-primarily based totally e-mail and net seek engine additionally voice to textual content conversion gadget as a way to resource the consumer who're naive to laptop structures to apply net centers in a hassle-loose manner. All features are primarily based totally on easy mouse click on operations making it very clean for any kind of consumer to apply this gadget. Also, the consumer wants now no longer fear approximately remembering which mouse click on operation he/she desires to carry out for user to avail a given carrier because the gadget itself might be prompting them as to which click on will offer them with what operations. The maximum usual place exiting mail offerings that we use in our everyday existence cannot be utilized by visually challenged humans. Speech popularity accuracy may be progressed in lots of ways, time frequency distribution HMM approach, may be used. Advances in voice popularity have made feasible packages in robotics managed through voice alone. On the alternative hand, Speech synthesis includes 3 categories: Concatenation Synthesis, Articulation Synthesis, and Formant Synthesis. In characteristic parameters for essential small gadgets of speech together with syllables, phonemes or one-pitch-duration speech, are saved and related through rules.
II. SPEECH ANALYSIS
In speech analysis method speech statistics incorporates specific styles of data that indicates a speaker identity. This consists of speaker unique data because of vocal tract, excitation supply and conduct feature. The bodily shape and measurement of vocal tract in addition to excitation supply are specific for every speaker. The speech evaluation offers with ranges with appropriate body length for segmenting speech sign for similarly evaluation and extracting. The speech analysis is done with following three techniques.
- Segmentation Analysis: In this case, speech is analyzed the usage of the body length and shift withinside the variety of 10-30ms to extract speaker facts. Studies had been made in the usage of segmented evaluation to extract vocal tract facts of speaker recognition.
- Sub-segmental Analysis: Speech analyzed the use of the frame length and shift in variety 3-5ms is called Sub segmental analysis. This method is used especially to research and extract the feature of the excitation state. The excitation supply statistics is quite speedy various as compared to vocal tract statistics, so small body length and shift are required to great seize the speaker-particular statistics.
- Supra-segmental Analysis: In this case, speech is analyzed via way of means of the use of the frame length and shift of 100-300ms to extract speaker facts particularly because of behavioral tract and right here speech is analyzed the use of the frame length. This approach is used particularly to investigate and feature because of conduct man or woman of the speaker. These consist of phrase duration, intonation, speaker rate, accessory etc.
III. TECHNIQUES FOR AUTOMATIC SPEECH RECOGNITION (ASR)
A. Artificial Intelligence Approach
AI technique is crossbred of sample reputation and acoustic phonetic method. This set of rules exploits the conceptions and mind of sample reputation and acoustic phonetic (AP) technique. Two simple approaches that to subsume superintend direct, set up orchestration is the entirety visible as used as a piece of ASR advanced version overseeing in putting of Dynamic Time Wrapping (DTW) and Stochastic technique to help in the use of hidden markov models. Every class to be visible is talked via way of means of possibly few or couple setups in DTW. Utilizing as barely of a manner over one reference consider each class can also be higher with a selected actual goal to improve the verbalization/speaker force displaying within the interior of confirmation, a package between a watched talk development and class mean is calculated to limit the effect of the scale bewilder amongst evaluation and point out outlines, prolonged and reshaped understandings of recommended technique extensively utilized available estimation
The mentioned phrase at seems the path through the version that constrains the amassed portion. Increase the quantity of sophistication pattern exchange and loosening enclosed barriers may improve dynamic time wrapping primarily based totally acknowledgment execution to inadequacy of the manner inquisitive and garage space. At satisfactory in category systems, hidden markov version-primarily based totally sample matching is rested in preference to dynamic time wrapping in context of decrease reminiscence requirement and better hypothesis properties.
B. Acoustic-Phonetic Approach
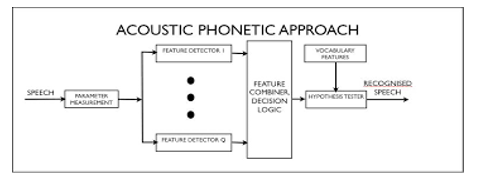
Speech reputation is based upon acoustics phonetics (AP) technique which hypothesizes that availability of the regular speech identified phrase evaluation function extraction re-agency speech reputation speaker identity speaker reputation supervised speech reputation unsupervised speech reputation remoted speech reputation non-stop speech reputation herbal language and discrete phonetic unit in talk’s dialects. phonetic devices are prominent through a method of phonetic parameters which confirmed up in the discourse sign or its fluctuation.
The steps of this approach are:
- Spectral analysis
- Segmentation and
- Labeling Determining valid word
In step one spectral evaluation of discourse joins with a feature identifier that progressed spectral dimensions into a group of traits which delineate the broader acoustic residences of the collected phonetic devices. Segmentation and labeling section gift that the discourse sign is segregated into regular acoustic zones, trailed via affiliation too many phonetic devices to every appropriated state, carrying out in phoneme lattice category of the speech. In 1/3 step develop amid this set of rules reveals to determine a appropriate string of phrases from the phonetic label succession created through the segmentation to labeling.
IV. SPEECH TO TEXT CONVERSION METHODS
Speech to text conversion is the system of changing spoken phrases into written texts. It is synonymous to speech popularity however the latter is used describe the broader system of speech understanding. STT follows the identical concepts and steps of speech popularity, with one-of-a-kind mixtures of diverse strategies for every step. Some widely used conversion methods are discussed below:
- Hidden Markov Model (HMM): HMM is a statistical version utilized in speech reputation due to the fact a speech sign may be considered as a piece wise stationary sign or a short-time desk bound sign. HMM, models are beneficial for real-time speech to textual content conversion for cellular users.
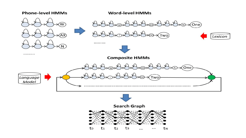
2. Artificial Neural Network Classier (ANN) based Search Optimization: ASR with Cuckoo Search Optimization method is used for higher communication, higher popularity and to dispose of undesirable noise. ASR is constructed for a higher interface of human and device interaction.

Conclusion
Speech Recognition System (SRS) is developing each day and has limitless applications. The study has proven the evaluation of the speech popularity process, its primary model, and applications. In this have a look at overall seven distinctive tactics which might be extensively used for SRS had been mentioned and after comparative have a look at of those tactics it\'s far concluded that Hidden markov method (HMM) is pleasant appropriate method for a SRS as it efficient, robust, and decreases time and complexity.
References
[1] https://cloud.google.com/speech-to-text [2] https://wca.wharton.upenn.edu/white-paper/voice-analytics-and-artificial-intelligence-future-directions-for-a-post-covid-world/ [3] https://towardsdatascience.com/beginners-guide-to-speech-analysis-4690ca7a7c05 [4] https://www.javatpoint.com/artificial-neural-network [5] https://www.datasciencecentral.com/artificial-neural-network-ann-in-machine-learning/ [6] https://asa.scitation.org/doi/10.1121/1.4744871 [7] https://usabilitygeek.com/automatic-speech-recognition-asr-software-an-introduction/
Copyright
Copyright © 2022 Mrs. Anuja A. V, Akshatha R, Jayaprakash M. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44803
Publish Date : 2022-06-24
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online