

Ijraset Journal For Research in Applied Science and Engineering Technology
Deepfake Video Detection Using LSTM and XRESNET
Authors: Varun P Shrivathsa
DOI Link: https://doi.org/10.22214/ijraset.2023.57056
Certificate: View Certificate
Abstract
As the rapid evolution of Artificial Intelligence continues, it becomes increasingly crucial to implement robust measures for monitoring and combating the proliferation of Deepfake videos. In this proposed method, frame-level features are extracted from videos using the XResNet convolutional neural network. These extracted features serve as the foundation for training the LSTM (Long Short-Term Memory) Recurrent Neural Network, enabling it to classify videos as either real or fake. Our dataset originates from Meta DFDC (Deepfake Detection Challenge) videos, selected for both the training and testing phases of our model. This model is able to predict a video with an accuracy of 83.3%.
Introduction
I. INTRODUCTION
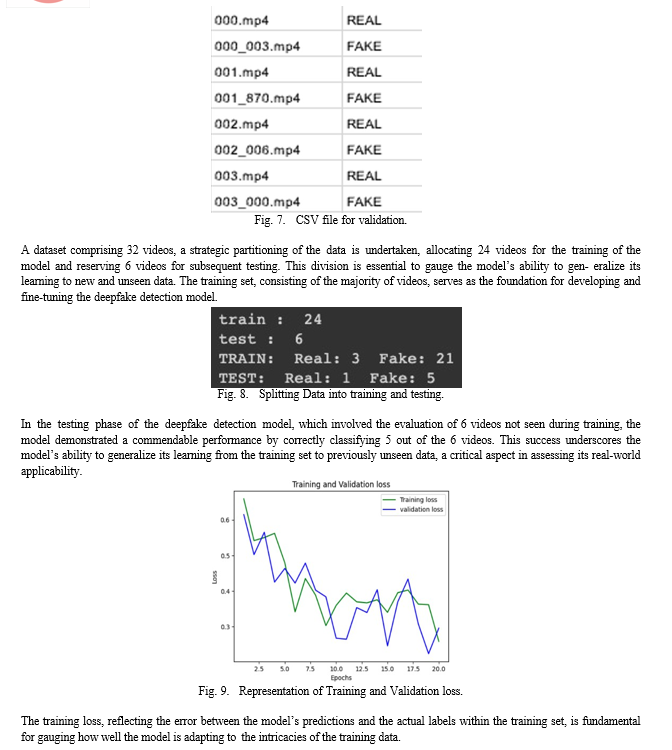
This project amalgamates two potent neural network ar- chitectures: XResNet, an evolution of ResNet designed for efficiency and performance, and LSTM (Long Short-Term Memory), known for its ability to understand temporal depen- dencies in sequential data. By combining these technologies, the project aims to create a comprehensive system capable of analyzing spatial and temporal features within video data, enhancing the accuracy and reliability of deepfake detection. XResNet is vital in the initial stages of the pipeline, utilizing its prowess in feature extraction. With a focus on facial features crucial for deepfake identification, XResNet captures intricate details and patterns, providing a strong foundation for subsequent analysis. The architecture’s efficiency is par- ticularly advantageous, ensuring that deep learning models can operate effectively even in resource-constrained envi- ronments. The 128 facial landmarks serve as key points of reference, enabling a deeper understanding of facial dynamics and expressions in various real-world scenarios. In essence, the fusion of XResNet with 128 facial landmark detection advances the accuracy of feature extraction. Complementing XResNet, the project leverages LSTM to analyze the temporal dynamics of video sequences. Videos are inherently sequen- tial, and LSTM’s ability to retain information over extended sequences proves invaluable. The temporal analysis augments the spatial understanding provided by XResNet, offering a holistic perspective on video content. The dataset employed in this project is sourced from the Meta Deepfake Detection Challenge (DFDC), which provides a diverse range of au- thentic and manipulated videos for training and evaluation. The neural networks are trained to discern subtle patterns indicative of deepfake manipulations, achieving an accuracy rate of 83.3%. Continuous monitoring and updates ensure the system’s adaptability to evolving deepfake techniques.
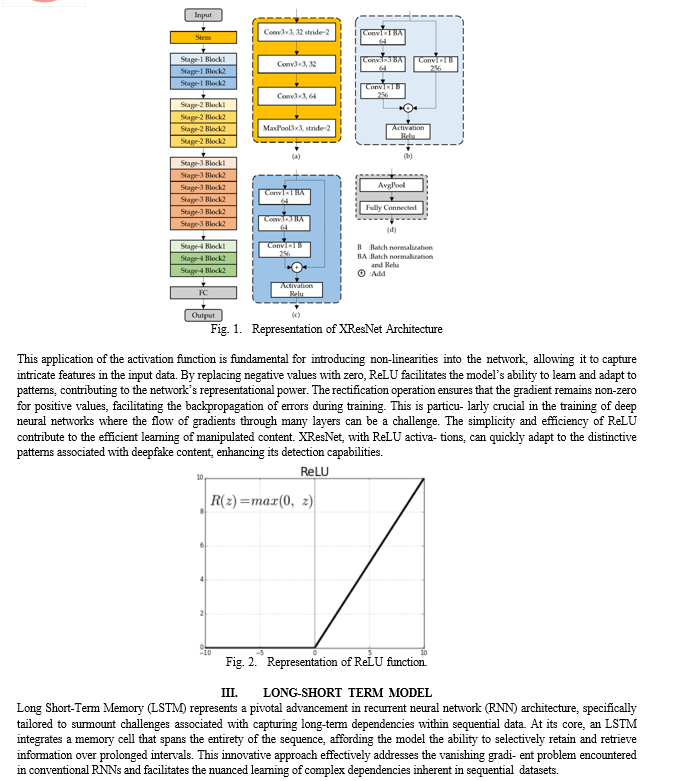
II. XRESNET AND RELU ACTIVATION FUNCTION
XResNet builds upon the foundational concepts of ResNet, enhancing them with key features to optimize performance.
At the core lies the deployment of residual blocks, which have proven instrumental in training exceptionally deep net- works. These blocks introduce shortcut connections, address- ing the vanishing gradient problem and facilitating the smooth flow of gradients through the network. This enables the successful training of models with an extended number of layers.
A distinguishing feature of XResNet is the incorporation of a ”stem block” at the beginning of the architecture. This block serves as the initial layer, efficiently capturing essential fea- tures from the input data and setting the stage for subsequent operations.
Convolutional layers play a central role in XResNet’s ar- chitecture, responsible for learning hierarchical features from the input data. These layers contribute to the network’s ability to understand complex spatial patterns and representations in the data. By focusing on the intricacies of facial patterns and expressions, it empowers deep fake detection systems with the ability to discern subtle variations indicative of manipulations.



Conclusion
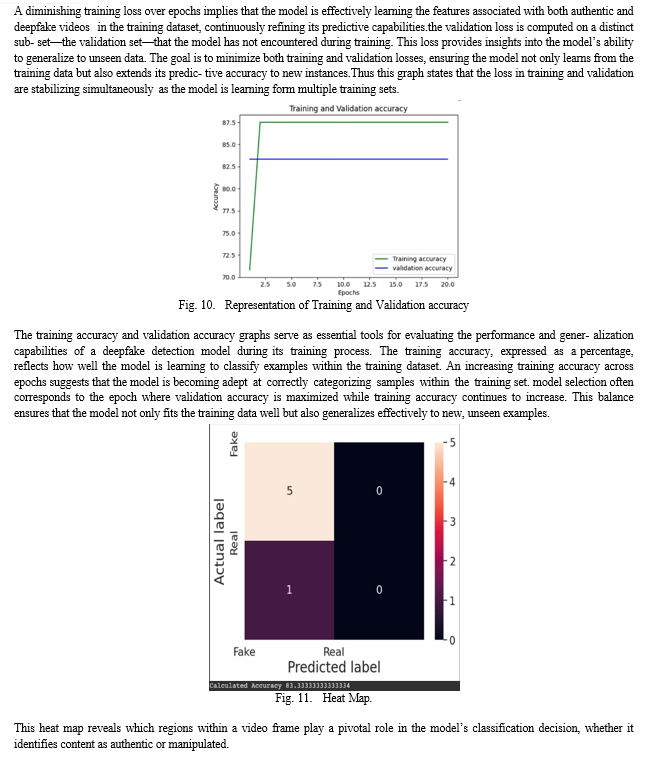
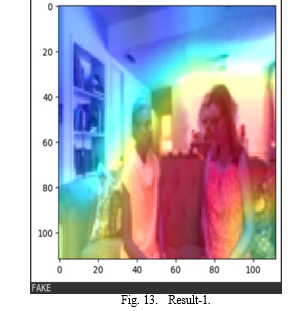
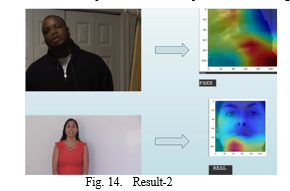
In conclusion, the deepfake video detection project employ- ing XResNet and LSTM showcases a promising fusion of spatial and temporal feature extraction techniques for robust model performance. The utilization of XResNet facilitates ef- fective extraction of spatial features, capturing intricate details within each frame, while the LSTM contributes by modeling temporal dependencies, considering the sequential nature of video data. The project, trained and tested on the Meta DFDC dataset, achieved a commendable accuracy of 83.3%, indicating the model’s ability to discern between authentic and deepfake content.The model is able to predict of the video is authentic or a fake and it also gives a optical flow chart indicating with red color on the presences of anomalies.Finally, the output of the LSTM, whether it be a refined feature representation or a prediction, is highlighted. The optical flow chart serves as a valuable tool for understanding the intricate changes and information dynamics within the LSTM network, providing an intuitive visual representation of its capabilities in handling sequential data.
References
[1] D. Afchar, V. Nozick, J. Yamagishi, and I. Echizen, ”MesoNet: a Compact Facial Video Forgery Detection Network,” in ACM Multimedia, 2018. [2] C. Feichtenhofer, A. Pinz, and R. P. Wildes, ”Spatiotem- poral Residual Networks for Video Action Recognition,” in NIPS, 2016. [3] A. G. Howard et al., ”Fastai: A Layered API for Deep Learning,” arXiv preprint arXiv:2002.04688, 2020. [4] M. Sundararajan, A. Taly, and Q. Yan, ”Axiomatic Attribution for Deep Networks,” in ICML, 2017. [5] M. Sabokrou, M. Khalooei, M. Fathy, and E. Adeli, ”Deep Anomaly Detection and Localization for Uncon- strained Face Verification,” in CVPR, 2018. [6] Y. Li et al., ”VIP-CNN: Visual Phrase Guided Convo- lutional Neural Network,” in CVPR, 2017. [7] I. Misra, C. L. Zitnick, and M. Hebert, ”Shuffle and Learn: Unsupervised Learning using Temporal Order Verification,” in ECCV, 2016. [8] X. Zhu, Z. Lei, X. Liu, H. Shi, and S. Z. Li, ”Face Alignment Across Large Poses: A 3D Solution,” in CVPR, 2016. [9] S. M. Lundberg and S.-I. Lee, ”A Unified Approach to Interpreting Model Predictions,” in NIPS, 2017. [10] Y. Qian, Y. Dong, and Y. Yang, ”DeepFake Video Detection Using Recurrent Neural Networks,” in Journal of Visual Communication and Image Representation, 2020.
Copyright
Copyright © 2023 Varun P Shrivathsa. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET57056
Publish Date : 2023-11-26
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online