

Ijraset Journal For Research in Applied Science and Engineering Technology
Emotion Recognition from Manipuri Language Using MFCC and Convolution Neural Network.
Authors: Gurumayum Robert Michael, Dr. Aditya Bihar Kandali
DOI Link: https://doi.org/10.22214/ijraset.2022.47463
Certificate: View Certificate
Abstract
Emotion recognition is a significant part in designing a better Human- Computer Interaction (HCI) System. Increasing applications of Emotion recognition from speech has been found in Education, gaming, medicine and automobiles industries. And after the Covid-19 pandemic identification of human emotions and action upon is the need of the hour. In this paper we try to identify four emotions by training a CNN model using Manipuri speech data set. We test our model using real time speech signal. Our model identifies sad emotion accurately but fails to identify angry emotion.
Introduction
I. INTRODUCTION
Emotion is one of the significant components that express individuals’ perspective. Human voice gives data about whether the speaker is happy or sad without looking at the person. The emotion state ingrained in the voice is a significant component that can be used alongside language and text for effective communication.
Two kinds of mediums have been recognized for human to human communication [1]: Explicit- that convey information through substantial message like language and Implicit- that conveys certain information, like emotions, that cannot be conveyed through explicit message. For more robust human-computer interaction (HCI), the computer should be able to perceive emotional state similarly as we human do. For more human like interaction with machine an HCI system should have both explicit message and implicit emotional delivery.
[2] Earlier we train a CNN model using Manipuri Speech data set. An accuracy of 46% was achieved in the model and an accuracy of 71 % is achieved using data augmentation. A 25% improvement is obtained by using combination of augmented and synthetic data. The accuracy measurement that we recorded above is based on the same dataset. In this report we applied a new recorded audio in our model and tried to predict the emotions. We input 10 audio signals in our model and predictions have been done. We observed how our model performs once we apply it to a completely new dataset with different audio quality, speaker and background noises. Our model does well in predicting the “sad” emotion but it has difficulty in predicting “angry “emotion.
II. MFCC
MFCC is a prevailing feature extraction method used in automatic speech recognition(SER).The coefficients are more sturdy and give great outcomes for noisy conditions.
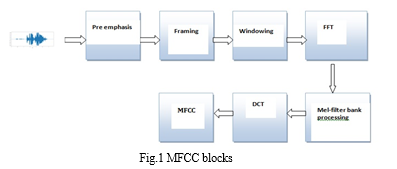

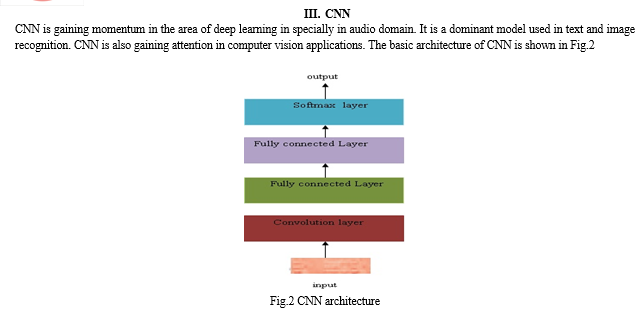
There are two essential parts of convolution neural network: a) Feature extraction b) classifier .After the feature extraction from the audio signal it is passed to a classifier to mapped the signals into their proper classes.
Our model is implemented using Keras model-level library with TensorFlow backend. Our model consist of 8 convolution channel with ReLu activation. It has 216x265 networks as input and the last layer is a dense layer or 192 neurons , followed by the classifier.
IV. RESULT AND DISCUSSION
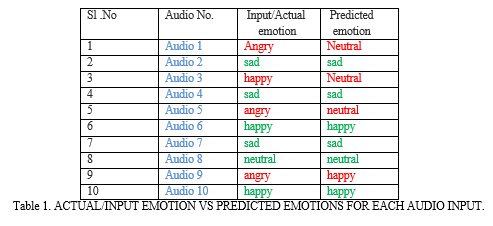
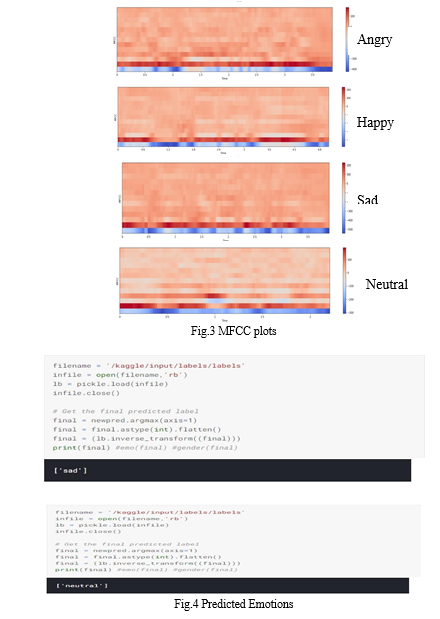
We ran the prediction for all the ten recorded audio file and the results is recorded in the given table no.1. We observed that our model identify sad emotion accurately but fails to identify angry emotion. The variation in the result may be due various reasons like the background noise or inaccurate emotion acted by our speaker while our model is trained on data from professional actor. Fig.3 shows MFCC plot of different emotions and Some of the predicted emotions are shown in Fig.4 .Further improvement has to be done and more real time data has to be collected to test our Model. The real challenges faced in collecting the data are to record real time emotional data.
Conclusion
In this paper we trained a CNN model using the Manipuri Speech data set. An accuracy of 46% was achieved in the model and an accuracy of 71 % is achieved using data augmentation. A 25% improvement is obtained by using a combination of augmented and synthetic data. We also observed that our model identifies sad emotion accurately but fails to identify angry emotion..Further improvement has to be done and more real time data has to be collected to test our Model. The real challenges faced in collecting the data are to record real time emotional data. The future work is to be train the model using more real time data to improve the accuracy.
References
[1] References I.Hong, Y.Ko,H.Shin,Y.Kim,”Emotion Recognition from Korean Language using MFCC, HMM, and Speech Speed”,ISSN 1975-4736,MITA2016 [2] G.R.Michael,A.B.Kandali,”Emotion recognition of Manipuri speech using convolution Neural Network.”,International journal od recent technology and Engineering,Vol-9,Issue 1,May 2020 [3] https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html [4] Lindasalwa Muda, Mumtaj Begam, and I. Elamvazuthi, “Voice recognition algorithms using mel frequency cepstral coefficient (MFCC) and dynamic time warping (DTW) techniques,” Journal of Computing, vol. 2, no. 3, pp. 138–143, Mar. 2010 [5] M.S. Likitha,1 Sri Raksha R. Gupta,2 K. Hasitha3 and A. Upendra Raju4,” “Speech Based Human Emotion Recognition Using MFCC “,International conference on wireless communication, signal processing and networking(WiSPNET), pp.2257-2260, March 2017 [6] Keras: The Python Deep Learning library, : https://keras.io
Copyright
Copyright © 2022 Gurumayum Robert Michael, Dr. Aditya Bihar Kandali. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET47463
Publish Date : 2022-11-14
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online