

Ijraset Journal For Research in Applied Science and Engineering Technology
Lane Detection for ADAS and AD Vehicles Using a Single Monocular Camera Using Python
Authors: Murali Manohar Yandra, Aarsha Mithra Vavilala, Meet Bhanushali
DOI Link: https://doi.org/10.22214/ijraset.2023.49964
Certificate: View Certificate
Abstract
These Lane Detection for ADAS and AD vehicles using a monocular camera using python and two different approaches of Hough Transform and Ultra Fast Structure-aware Deep Lane Detection trained on CULane dataset on ResNet18- UFast and compare them based on F1 score and complexity (computational time).
Introduction
I. INTRODUCTION
The rapid development of society has led to the widespread use of automobiles as one of the primary means of transportation for people. The more narrow the road becomes, the more vehicles of all kinds are seen. As more and more vehicles are on the road, the number of car accidents is increasing each year. Driving safely on crowded streets and roads has become a focus of attention, given the number of vehicles and narrow lanes. Advanced driver assistance systems that include lane departure warning (LDW), lane keeping assist, and adaptive cruise control (ACC) can help drivers understand the current driving environment and provide appropriate feedback for safe driving or alert the driver in dangerous circumstances. This kind of auxiliary driving system is expected to become better and better over time. This system has a difficulty in developing because the traffic environment is difficult to predict. In the complicated traffic environment where there are many vehicles and speeds are too high, the probability of accidents is usually greater than usual. In a complex traffic situation, the main perceptual clues that a human driver uses to navigate are extraction of road colour and texture, detection of road boundaries and lanes, and marking of the road. Lane detection is a popular topic in machine learning and computer vision, and it's been used in intelligent vehicle systems. The lane detection system relies on lane markers in a complex environment to estimate a vehicle's position and trajectory relative to the lane reliably. The lane departure warning system relies on both lane detection techniques - Hough transform and Ultra Fast Structure-aware Deep Lane Detection - to provide accurate warnings. In this project, we will be working with two of the most popular methods.
II. EXPERIMENT
Hough Transform Procedure
A. Processing a video
To feed in video for lane detection as a series of continuous frames (images) by intervals of 10 milliseconds. Quit the program anytime by pressing the ‘q’ key.
B. Applying Canny Detector
The Canny Detector is a fast and accurate algorithm for detecting edges in images. The goal of the algorithm is to detect large gradients in luminosity (changes from white to black), and define them as edges, given a set of thresholds. The Canny algorithm has four main steps:
- Noise Reduction
Like all edge detection algorithms, noise can cause false detection, which can be a problem. A 5x5 Gaussian filter is applied to smooth the image to lower the detector's sensitivity to noise. The algorithm uses a kernel of normal numbers to calculate the pixel values across the image, weighted by the distance between each pixel and its nearest neighbor.

2. Intensity Gradient
The smoothened image is then applied with a Sobel, Roberts, or Prewitt kernel (Sobel is used in OpenCV) to detect whether the edges are horizontal, vertical, or diagonal.
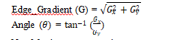
3. Non Maximum Suppression
Non-maximum suppression is used to sharpen the edges of "thin" images. For each pixel, the value is checked to see if it is the local maximum in the direction of the gradient calculated previously.
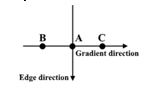
4. Hysteresis thresholding
After non-maxima suppression, strong pixels are confirmed in the final edge map. However, the weak pixels need to be further analyzed to determine if they constitute a edge or noise. We use two pre-defined threshold values to determine which pixels are edges and which pixels are not. If the intensity gradient of a pixel is higher than the maximum threshold value, then the pixel is considered an edge; if the intensity gradient of a pixel is lower than the minimum threshold value, then the pixel is not considered an edge. We then discard these pixels. Only pixels with intensity gradients between minVal and maxVal will be considered edges. If they are connected to a pixel with a higher intensity gradient, then they will be considered an edge.
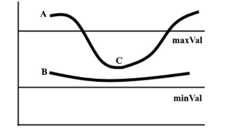
Edge A is higher than the maximum value so it is an edge. Edge B is between the maximum value and the minimum value, but it is not connected to any edge above the maximum value, so it is discarded. Edge C is between the maximum value and the minimum value and is connected to edge A, an edge above the maximum value. This means that C is an edge. For our pipeline, we first grayscale the image to reduce noise and then apply a 5 by 5 gaussian blur to decrease the amount of noise.
C. Segmenting Lane
Handcraft a triangular mask to segment the lane area and discard the irrelevant areas in the frame to increase the effectiveness for the later stages.
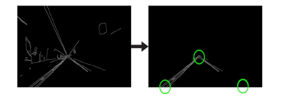
D. Hough Transform
In the Cartesian coordinate system, we can represent a straight line as y = mx + b by plotting y against x. However, we can also represent this line as a single point in Hough space by plotting b against m. For example, a line with the equation y = 2x + 1 may be represented as (2, 1) in Hough space.

There are many possible lines which can pass through this point, each with a different value for the parameters m and b. For example, a point at (2, 12) can be passed by y = 2x + 8, y = 3x + 6, y = 4x + 4, y = 5x + 2, y = 6x. These points can be plotted in Hough space as (2, 8), (3, 6), (4, 4), (5, 2), (6, 0).You can see that this line produces a vector in Hough space with a m component against a b component.
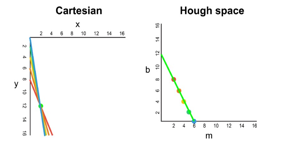
Whenever we see a series of points in a Cartesian coordinate system and know that these points are connected by some line, we can find the equation of that line by first plotting each point in the Cartesian coordinate system to the corresponding line in Hough space, then finding the point of intersection in Hough space. The point of intersection in Hough space represents the m and b values that pass consistently through all of the points in the series.
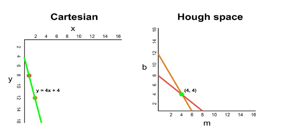
Since our frame passed through the Canny Detector, it may be interpreted as a series of white points representing the edges in our image space. We can use the same technique to identify which of these points are connected to the same line, and if they are connected, what its equation is so that we can plot this line on our frame. We used Cartesian coordinates to map out Hough space. However, there is a mathematical flaw with this approach: when the line is vertical, the gradient is infinite and cannot be represented in Hough space. To solve this problem, use polar coordinates instead. The process is still the same, just that we'll be plotting r against θ rather than m against b in Hough space.
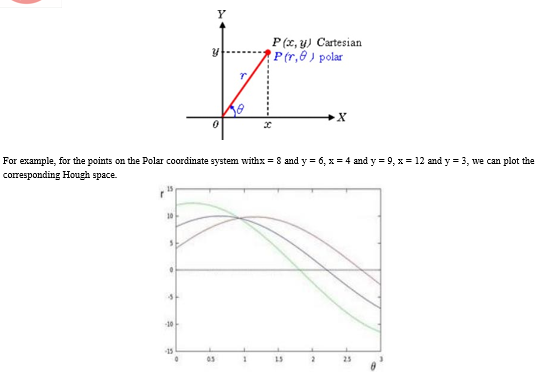
We see that the lines in Hough space intersect at θ = 0.925 and r = 9.6. Since a line in the Polar coordinate system is given by r = xcosθ + ysinθ, we can induce that a single line crossing through all these points is defined as 9.6 = xcos0.925 + ysin0.925.
Generally, the more curves intersecting in the Hough space, the more points corresponding to the straight line represented by the intersection. We will require a minimum number of intersections in Hough space in order to detect a line. Hough transformation keeps track of the intersections of Hough spaces for every point in the frame. If the number of intersections exceeds a defined threshold, we identify a line with the corresponding θ and r parameters. We use the Hough transform to identify two straight lines that will be our left and right lane boundaries.
E. Use of CNN
CNN is a kind of deep neural network that consists of several hidden layers, such as the RELU layer, the convolutional layer, the pooling layer and the fully linked optimizer layer. CNN's weights are shared among its neurons, which reduces its memory requirements and improves network performance. The convolutional layer generates a feature vector by convolving various sub-regions of the source images with a learned kernel. Then, a nonlinear activation function is applied to speed up the convergence rate when the error is minimal.
The pixels in the selected section are averaged to create a single value. The pixels with the highest value are preferred. This results in a large decline in the sample size. The conventional Fully Connected (FC) layer is often used in accordance with the extent of the input layer's convolution. Typically, two different kinds of pooling are done by the pooling layer: maximum pooling and mean pooling. The neighbourhood used for the typical calculation is limited to the features that were extracted in the case of mean pooling, and the maximum number of features is used for the max pooling calculation. This limits the error caused by the small size of the neighbourhood, and retains useful background information.
- Ultra Fast Structure -aware Deep Lane Detection
We have made the proposed modification of the paper “Ultra Fast Structure -aware Deep Lane Detection” as below
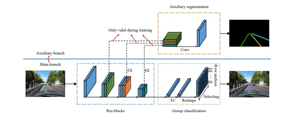
Using the model weights provided by the author trained on the CULane dataset we will be running a Python file that uses Opencv for live video capture and this model gives us the desired result that is lanes are detected
2. Comparison
Based on their performance on the CULane dataset *Hough transform result is obtained when a DNN approach is applied unlike in this project (ref 7) to it since comparable metrics aren’t available for applying Hough transform
|
Model |
F1 score |
|
Hough Transform |
69.86 |
|
UFast |
69.7 |
Even though the Hough transform appears to offer an additional boost when compared to DNN and approximation techniques that followed in that paper, the best case scenario as of date is using the Hough transformer on roads that are not a straight line. This is because Hough transforms are used for shapes like lines and curves, which can be more challenging to work with in certain weather conditions. The Hough transform is only effective if a high number of votes fall in the right bin, so that it can be easily detected amid the background noise. This means that the container cannot be too small, otherwise some voices will fall into the neighboring containers, reducing the visibility of the main container.
Conclusion
While Hough transform and UFAST are two separate approaches to the problem the nature of the algorithm in Hough transform makes it unsuitable for real world driving scenario while using CNN for this problem will be dependent on training costs and better and smaller CNN are being developed.
References
[1] Mingfa Li, Yuanyuan Li, Min Jiang, \"Lane Detection Based on Connection of Various Feature Extraction Methods\", Advances in Multimedia, vol. 2018, Article ID 8320207, 13 pages, 2018. https://doi.org/10.1155/2018/8320207 [2] Qiu, D., Weng, M., Yang, H., Yu, W. and Liu, K., 2019, June. Research on Lane Line Detection Method Based on Improved Hough Transform. In 2019 Chinese Control And Decision Conference (CCDC) (pp. 5686-5690). IEEE. [3] Wu, P.C., Chang, C.Y. and Lin, C.H., 2014. Lane-mark extraction for automobiles under complex conditions. Pattern Recognition, 47(8), pp.2756-2767. [4] Qin, Z., Wang, H. and Li, X., 2020, August. Ultra fast structure-aware deep lane detection. In European Conference on Computer Vision (pp. 276-291). Springer, Cham
Copyright
Copyright © 2023 Murali Manohar Yandra, Aarsha Mithra Vavilala, Meet Bhanushali. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET49964
Publish Date : 2023-03-31
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online