

Ijraset Journal For Research in Applied Science and Engineering Technology
Machine Learning Models for Predicting Air Pollution
Authors: Arpan Ghosh, Vansh Nanda, Tushar Bansal, Er. Reshma
DOI Link: https://doi.org/10.22214/ijraset.2023.57080
Certificate: View Certificate
Abstract
The air quality monitoring system collects data of pollutants from different location to maintain optimum air quality. In the current situation, it is the critical concern,. The introduction of hazardous gases into the atmosphere from industrial sources, vehicle emissions, etc. pollutes the air. Today, the amount of air pollution in large cities has surpassed the government-set air quality index value and reached dangerous levels. It has a significant effect on a human health. The prediction of air pollution can be done by the Machine Learning (ML) algorithms. Machine Learning (ML) combines statistics and computer science to maximize the prediction power. ML is used in order to calculate the Air Quality Index. Various sensors and an Arduino Uno microcontroller are utilized to collect the dataset. Then by using K- Nearest Neighbor (KNN) algorithm, the air quality is predicted.
Introduction
I. INTRODUCTION
Among the most crucial challenges faced in the world today is air pollution. Industrial activity is increasing more regularly due to the explosive growth of economy, which is causing air pollution to increase more rapidly. Environmental pollution is a serious issue that affects all living things, including humans, with pollution from industry accounting for a significant portion of it. Solid particles such as dust, pollen, and spores, and gases, contribute to air pollution. Carbon monoxide, Carbon dioxide, Nitrogen dioxide, Sulphur oxide, Chlorofluorocarbons, Particulate Matter, and other air pollutants that cause air pollution are released by the combustion of natural gas, coal, and wood, as well as factories, cars, and other sources. Prolonged exposure to air pollution leads to serious health problems, such as lung and respiratory illnesses
The annual death toll from household exposure to gasoline smoke is 3.8 million. Exposure to the outdoor air pollution will cause 4.2 million deaths annually. 9 out of 10 people on the earth reside in areas with air quality that is worse than recommended by the World Health Organization. As per the Greenpeace Southeast Asia Analysis of IQAir statistics, air pollution and associated problems caused over 120,000 deaths in India in 2020.According to the report, air pollution caused economic losses of ?2 lakh crore in India. This demonstrates how crucial it is to pay attention on the air quality.
Primary pollutants and the secondary pollutants are the two major classifications of air pollutants. One that is directly emitted into the atmosphere from its source is referred to as a primary pollutant, whereas a secondary pollutant is one that is produced due to the interaction between two primary pollutants or with other elements of the atmosphere. One of the detrimental effects of pollutants emitted into the environment is the degradation of air quality. Also, other harmful effects, such as acid rain, global warming, aerosol production, and photochemical smog has increased in past years.
Predicting the air quality is crucial for preventing the problem of air pollution. The Machine Learning (ML) models can be used for this. With the use of training data, a computer can learn how to build models via a technique called as Machine Learning. It is a branch of Artificial Intelligence that gives computer program the ability to forecast outcomes with ever-increasing accuracy. ML can examine a variety of data and identify patterns and particular trends. Machine learning is the ability given to a computer program to do a task without any external programming and this is task is achieved by using some statistical and advanced mathematical algorithms.
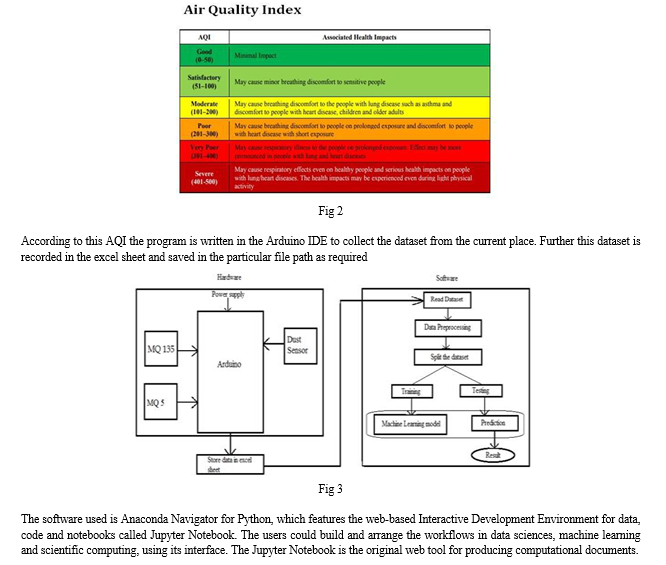
As air pollution has been rising every day, monitoring has proven to be a significant task. The amount of pollution in a given area is determined through continuous air quality monitoring at that location. The information obtained by the sensors reveals the source and concentration of the pollutants in that area. Measures to minimise pollution levels can be taken usingthat knowledge and the ML model. The hardware device consists of three different sensors like MQ-135 air quality sensor, MQ-5 sensor, Optical dust sensor connected to the Arduino uno board, which helps in collecting the pollutants information of the currentplace.
II. LITERATURE SURVEY
The authors of [1] proposed that Machine Learning algorithms plays important role in measuring air quality index accurately. Logistic regression and auto regression, ANN help in determining the level of PM2.5. ANN comes out with best results in the paper.
In [2] authors gives the prediction of the air quality index by using different machine learning algorithms like Decision Tree and Random Forest. From the results, concluded that the Random Forest algorithm gives better prediction of air quality index.
In [3] authors proposed model by using BILSTM which is the Deep Learning model to predicted the PM2.5 with improved performance comparing the existing model and produced exceptional MAE, RMSE.
In [4] authors used the prediction model results were based on Big Data Analytics and Machine Learning, which have helped to evaluate and contrast current assessments of air quality. The Decision Tree algorithm gave the best results among all the algorithms.
The authors of [5] used SVR, and LSTM Machine Learning models. The Machine Learning algorithms used for estimating the atmospheric pollutants (PM10 and PM2.5), it was demonstrated that SVR algorithms are the most suitable in forecasting the air pollutants concentrations.
This study focused on machine learning algorithms to predict air quality indices and pollutant concentrations. The research, published in Applied Sciences, demonstrated the potential of machine learning in accurately forecasting air quality parameters, highlighting the practical applications of these algorithms.[6]
The paper introduced a machine learning framework specifically tailored for predicting air quality in California. Published in Complexity, the research delved into the complexities of Californian air quality and proposed innovative machine learning techniques, providing a comprehensive understanding of the region's pollution dynamics.[7]
Focusing on Chennai, this research employed regression and ARIMA time series models to predict air quality indices. Published in the Journal of Engineering Research, the study showcased the efficacy of combining traditional statistical methods with advanced machine learning, offering a nuanced approach to air quality prediction.[8]
This paper [9] presented an integrated model employing Artificial Neural Networks (ANN) and Kriging for forecasting air pollutants. Published in the International Journal of Advanced Research in Computer, Communication Engineering, the research underscored the importance of incorporating meteorological data into machine learning models, enhancing the accuracy of air pollution predictions. Focused on supervised machine learning algorithms, this study[10], published in the International Journal of Scientific Research in Computer Science, Engineering, and Information Technology, presented a robust air quality prediction model. The research emphasized the significance of algorithm selection and training data quality in building effective prediction systems.
III. METHODOLOGY
In this paper, the proposed methods use three different algorithms to draw a comparative analysis of the AQI values of New Delhi, Bangalore, Kolkata, and Hyderabad by using parameters such as PM2.5, PM10, NO, NO2, NOx, NH3, CO, SO2, O3, Benzene, and toluene levels, which will then compare the three algorithms and find the most accurate and efficient algorithm. The aim is to analyze and present it in an efficient way. It would help us discover interesting and insightful information. These particular cities have a higher population density and give a good estimate of the pollution in a major South Asian city. More cities have not been added due to the fact that it makes the research paper way too lengthy. Hence, the major cities of India have been chosen to analyze the pollution levels in different urban cities of India as they are the major contributors to pollution.
Some of the existing algorithms used are Naive Bayes-a Bayes theorem-based classifier, support vector machine-a supervised learning model for classification and regression, artificial neural network-learning methodology inspired by actual neurons of the brain, gradient boost-techniques utilizing an ensemble of weak prediction models, decision tree-which works by making predictive models using data, and k-nearest neighbor-a lazy learning nonparametric supervised method.
The proposed algorithms used and compared are given below.
A. Synthetic Minority Oversampling Technique (SMOTE) Algorithm
Synthetic samples are created for the minority class using this oversampling technique. It aids in making an imbalanced dataset balanced. This approach helps with beating the issue of overfitting brought about by arbitrary oversampling.
B. Support Vector Regression
It is a discrete value prediction technique that uses supervised learning. For comparable purposes, SVMs and support vector regression are likewise used. Finding the most appropriate line is the main tenet of SVR. In SVR, the hyperplane with the most points is the line that fits the data the best.
C. Random Forest Regression (RFR) Algorithm
It is a frequently used supervised machine-learning technique for classification and regression problems. It creates decision trees based on a variety of samples, utilizing the average for regression and the classification vote.
D. CatBoost Regression (CR) Algorithm
Yandex has developed a library of open-source software. It offers a framework for gradient boosting which, unlike the standard technique, aims at resolving categorical features using an alternative based on permutation. All the three algorithms showed promising results in other works which had been studied through the literature survey. These three algorithms were chosen due to their high accuracy in previous different works, and with the proposed work, the aim is to draw a comparative analysis and find the one with the best accuracy with balanced and imbalanced datasets. The aim is to use them and apply them to the Bangalore, Kolkata, Hyderabad, and New Delhi datasets and compare their accuracies to figure out what best fits our use case. The picked algorithms have the highest accuracy based on our extensive literature survey, used for the AQI prediction. The algorithms being used for prediction are support vector regression (SVR), random forest regression (RFR), and CatBoost regression (CR). These algorithms will be provided with a suitably large dataset of cities, such as New Delhi, Bangalore, Kolkata, and Hyderabad, and will provide a practical environment. The dataset used will be cleaned, reduced, and prepared according to our requirements and the data will be split into training and testing data. The plan is to use the simplest, most straightforward implementation in order for the algorithms to be applied easily in a real-life use case. Then, different parameters will be taken to finalize and draw up a comparison between these 3 algorithms and then come to the conclusion to show which is the most accurate. The comparison can bring out important information about AQI prediction methods and even help us choose the most suitable one. A comparison of the accuracy levels obtained with an imbalanced dataset and a balanced dataset with the help of the SMOTE algorithm will also be done.
Hence, the methodology is a step-by-step process in which the first step is to find a suitable dataset and clean it. After this, further data preprocessing is applied which makes use of SMOTE in order to balance the dataset. Both balanced and imbalanced datasets will be preserved and used in order to bring to light any differences in performance that may arise due to balancing. Following this, in a standard machine learning procedure, the dataset is split into train and test to train the models and test their accuracies against real data. Feature scaling and normalization are carried out. Now, each regression model which has been picked, namely, random forest, support vector regression, and CatBoost, are used for prediction and its accuracy is gauged, for each balanced and imbalanced dataset as mentioned previously. They are compared using metrics such as RMSE and R-SQUARE. Finally, all the data and results have been displayed using clear figures, graphs, and charts which easily make one understand what exactly has led to the increase in accuracy and hence help future research. Various steps which will be performed during the implementation of this work to achieve the determined result. The flowchart is a process-based flowchart that shows the steps of the process in a detailed manner. It has been derived from the actual working out into running these models and extracting results. The process flowchart is drawn in Western ANSI standards.
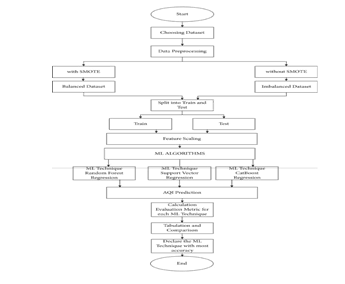
- Step 1: Choosing a dataset Choosing an extensive dataset from Kaggle according to our requirements and downloaded its CSV file.
- Step 2: Data preprocessing In data preprocessing, they cleaned the original dataset and extracted the New Delhi, Bangalore, Kolkata, and Hyderabad city data. Because these are major cities in India, it is important to analyze the pollution levels in different urban cities in India as they are the major contributors to the pollution. These particular cities have a higher population density and give a good estimate of the pollution. Each of these datasets was cleaned by removing all null value rows, and the attribute xylene was removed from the dataset due to the fact that the column values were empty for all 4 cities chosen, hence making it a redundant attribute. Microsoft Excel software is used to remove unnecessary, irrelevant, and erroneous data.
- Step 3: Applying the SMOTE algorithm After the cleaning of the dataset, the synthetic minority oversampling technique (SMOTE) is used to correct the class imbalances in the AQI_Bucket values. Delhi, Bangalore, Kolkata, and Hyderabad required 3, 11, 9, and 24 manual iterations to achieve a suitable level of balance. This is carried out to create a balanced version of the dataset.
- Step 4: Not applying the SMOTE algorithm. Here, the synthetic minority oversampling technique (SMOTE) is not applied to the dataset it is being used directly just after removing unnecessary, irrelevant, and erroneous data in it and hence is in its imbalanced form.
- Step 5: Splitting of the dataset The datasets are split into training and test data at an 80 : 20 ratio. These are used to train the model and then test it against the original data. The values predicted by the machine learning algorithms are corroborated with the original data to predict accuracy.
- Step 6: Training the dataset Empirical studies show that the best results are obtained if 80% of the data is used for training. Random sampling is used as a way to divide the data into train and test sections. It is widely accepted and is very popular.
- Step 7: Testing the dataset Empirical studies show that the best results are obtained if the remaining 20% of the data is used for testing. Random sampling is used as a way to divide the data into train and test sections. It is widely accepted and is very popular.
- Step 8: Feature scaling The data have been normalized in order to make the dataset flexible and consistent. StandardScaler from Scikit-Learn Library has been used to do so. It normalizes the features by deleting the mean and scaling the unit variance.
- Step 9: Applying machine learning (ML) techniques After normalizing the range of features in the datasets, various algorithms, namely, CatBoost regression, random forest regression, and support vector regression are used to forecast air quality index, and then, they are compared to show which algorithm gives the best accuracy level for each city, respectively.
- Step 10: Applying ML technique-random forest regression Random forest is a supervised machine learning algorithm that is used for classification and regression problems. It creates decision trees from several samples, using the majority vote for classification and the average in the case of regression. A random forest produces precise predictions that are easy to understand. Effective handling of large datasets is possible.
- Step 11: Applying ML technique-support vector regression Support vector regression is a supervised machine learning algorithm that is used for regression problems. Discrete values can be predicted using it. The core idea of SVR is locating the best fit line. The SVR best -fitting line is the hyperplane with the most points. The flexibility of SVR allows us to decide how much error in our model is acceptable.
- Step 12: Applying ML technique-CatBoost regression A supervised machine learning approach called CatBoost regression is based on gradient-boosted decision trees. During training, a number of decision trees are constructed progressively. To generate a powerful, competitive predictive model through greedy search, the main objective of boosting is to successively integrate a large number of weak models or models that only marginally outperform chance. It has a quick inference process since it uses symmetric trees and its boosting techniques aid in lowering overfitting and enhancing model quality.
- Step 13: AQI prediction Machine learning techniques are used to aid in this process, and the accuracy level of AQI for each city is estimated. The values are tabulated and graphs depicting the accuracy levels of all 4 cities are plotted.
- Step 14: Calculation of evaluation metric for each ML technique. The metrics used for the proposed work are R -SQUARE, MSE, RMSE, MAE, and the accuracy (1-MAE) of CatBoost regression, random forest regression, and support vector regression.
- Step 15: Tabulation and comparison Taking all the metric values obtained after running the machine learning techniques (i.e.,) R-SQUARE, MSE, RMSE, MAE, and the accuracy of the algorithms. For comparison tabulating, the predicted values and actual values for each city and model and plot multiple graphs such as line graphs, density plots, and scatter plots are analyzed. All metric values and accuracy values of each city and model are further tabulated, plotting bar graphs to compare the accuracy of each model city-wise and also plot bar graphs to compare R-SQUARE, MSE, RMSE, and MAE values of each model city-wise. Here, the accuracy is calculated using various cities datasets with SMOTE applied to them, repeating the same steps from Step 10 to Step 15 after using the dataset with the SMOTE algorithm applied.
- Step 16: Final comparative results (declare the ML technique with the highest accuracy) Once tabulated all the values, the next step is to compare the metric values of all the used algorithms and see what best fits the scenario. In the proposed work, random forest and CatBoost regression are the best performances overall. RFR got the best RMSE values in Bangalore, Kolkata, and Hyderabad, whereas CatBoost regression performed best in Delhi. The highest accuracy was obtained by random forest regression for the cities of Kolkata and Hyderabad and New Delhi and Bangalore. CatBoost regression gave the highest accuracy. The tabulated values are compared with metric values before and after applying SMOTE on the dataset to find what gives better accuracy. In the proposed work, random forest and CatBoost were the best performances overall.
IV. IMPLEMENTATION
The Central Pollution Control Board of India provided the AQI in the report National Air Quality Index, which is shown in the Fig 2 below


Conclusion
The quality of the air is determined by components like gases and particulate matter. These pollutants decrease the air quality, which can lead to serious illnesses when breathed in repeatedly. With air quality monitoring systems, it is possible to identify the presence of these toxics and monitor air quality in order to take sensible measures to enhance air quality. As a result, production rises and health problems caused by air pollution are reduced. The prediction models built using machine learning have been shown to be more reliable and consistent. Data collecting is now simple and precise due to advanced technology and sensors. Only machine learning (ML) algorithms can effectively handle the rigorous analysis needed to make accurate and efficent predictions from such vast environmental data. In order to predict air pollution, the KNN algorithm is used, which is better suitable for prediction tasks.
References
[1] Shreyas Simu,Varsha Turkar, Rohit Martires, “Air Pollution Prediction using Machine Learning”, 2020, IEEE [2] Tanisha Madan, Shrddha Sagar, Deepali Virmani, “Air Quality Prediction using Machine Learning Algorithms”, 2020, IEEE [3] Venkat Rao Pasupuleti, Uhasri , Pavan Kalyan, “Air Quality Prediction Of Data Log By Machine Learning”, 2020 , IEEE [4] S. Jeya, Dr. L. Sankari, “Air Pollution Prediction by Deep Learning Model”, 2020, IEEE [5] SriramKrishna Yarragunta, Mohammed Abdul Nabi, Jeyanthi.P, “Prediction of Air Pollutants Using Supervised Machine Learning”, 2021, IEEE [6] H. Liu, Q. Li, D. Yu, and Y. Gu, “Air quality index and air pollutant concentration prediction based on machine learning algorithms,” Applied Sciences, vol. 9, p. 4069, 2019. [7] M. Castelli, F. M. Clemente, A. Popovic, S. Silva, and L. Vanneschi, “A machine learning approach to predict air quality in California,” Complexity, vol.2020, Article ID 8049504, 23 pages, 2020. [8] G. Mani, J. K. Viswanadhapalli, and A. A. Stonie, “Prediction and forecasting of air quality index in Chennai using regression and ARIMA time series models,” Journal of Engineering Research, vol. 9, 2021. [9] S. V. Kottur and S. S. Mantha, “An integrated model using Artificial Neural Network (ANN) and Kriging for forecasting air pollutants using meteorological data,” Int. J. Adv. Res. Comput. Commun. Eng, vol. 4, pp. 146–152, 2015. [10] S. Halsana, “Air quality prediction model using supervised machine learning algorithms,” International Journal of Scientific Research in Computer Science, Engineering and Information Technology, vol. 8, pp. 190–201, 2020. [11] Hasbeh, M. Ahmadi Alvar, K. Y. Aghdam, H. Ghorbani, N. Mohamadian, and J. Moghadasi, “Hybrid computing models to predict oil formation volume factor using multilayer perceptron algorithm,” Journal of Petroleum and Mining Engineering, vol. 23, no. 1, pp. 17–30, 2021. [12] F. Jafarizadeh, M. Rajabi, S. Tabasi et al., “Data driven models to predict pore pressure using drilling and petrophysical data,” Energy [13] G. Zhang, S. Davoodi, S. S. Band, H. Ghorbani, A. Mosavi, and M Moslehpour, “A robust approach to pore pressure prediction applying petrophysical log data aided by machine learning techniques,” Energy Reports, vol. 8, pp. 2233– 2247, 2022. [14] S. Tabasi, P. Soltani Tehrani, M. Rajabi et al., “Optimized machine learning models for natural fractures prediction using conventional well logs,” Fuel, vol. 326, Article ID 124952, 2022. [15] M. Rajabi, O. Hazbeh, S. Davoodi et al., “Predicting shear wave velocity from conventional well logs with deep and hybrid machine learning algorithms,” Journal of Petroleum Exploration and Production Technology, 2022. [16] S. Beheshtian, M. Rajabi, S. Davoodi et al., “Robust computational approach to determine the safe mud weight window using well-log data from a large gas reservoir,” Marine and Petroleum Geology, vol. 142, Article ID 105772, 2022. [17] Z. K. Masoud, S. Davoodi, H. Ghorbani et al., “Band, Permeability prediction of heterogeneous carbonate gas condensate reservoirs applying group method of data handling,” Marine and Petroleum Geology, vol. 139, 2022. [18] N. Mohamadian, H. Ghorbani, D. A. Wood, and M. A. Khoshmardan, “A hybrid nanocomposite of poly(styrene-methyl methacrylate- acrylic acid)/clay as a novel rheology-improvement additive for drilling fluids,” Journal of Polymer Research, vol. 26, no. 2, p. 33, 2019. [19] N. Mohamadian, H. Ghorbani, D. A. Wood, and H. K. Hormozi, “Rheological and filtration characteristics of drilling fluids enhanced by nanoparticles with selected additives: an experimental study,” Advances in Geo-Energy Research, vol. 2, no. 3, pp. 228–236, 2018.
Copyright
Copyright © 2023 Arpan Ghosh, Vansh Nanda, Tushar Bansal, Er. Reshma. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET57080
Publish Date : 2023-11-27
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online