

Ijraset Journal For Research in Applied Science and Engineering Technology
Parkinson’s Disease Detection using Machine Learning Algorithms
Authors: Amreen Khanum D, Prof. Kavitha G, Prof. Mamatha H S
DOI Link: https://doi.org/10.22214/ijraset.2022.46272
Certificate: View Certificate
Abstract
The main goal of the study is to inspect the performance of the different Supervised Algorithms for the improving the Parkinson Disease diagnosis by detection. We have used Five machine learning techniques for the detection of Parkinson Disease datasets. KNN,LR,DT,NB and XGBoost were used for the prediction of Parkinson Disease. The Performance of the classifiers is evaluated via, precission, Accuracy, F1-Score, Recall and Support. Where after computing with different classifier we got result as KNN shows the accuracy level 96% for Parkinson Disease. XGBoost achieved the second highest classification accuracy of 91%. Moreover, in the terms of accuracy for analyzing the Parkinson Disease dataset ,NB achieved the lowest accuracy of 76%. In our study has emphasized the current Parkinson Disease research trends and scope in relational to clinical research fields by machine learning technique .That will be effective impact in field of Parkinson Disease.
Introduction
I. INTRODUCTION
Parkinson's diseases is a Neurodegenerative disease It is a progressive pathology that affects the brain and the nervous system, leading. to the death of nerve cells. The most known and frequent ones are Alzheimer's and Parkinson's diseases Parkinson’s disease, is particularly linked to the loss of dopamine producing neurons in the basic ganglia. which has human, social and financial impacts, on a personal, professional and social level. The medication fees for Parkinson's disease are very expensive. At the moment, no cure has been found. Medication is limited to treatments, at an early stage, to improve the patient's quality of life. Several methods have been used to detect the symptoms of Parkinson's disease, but most of them require motor actions that appear only in an advanced state of the disease. Most used traditional methods for the determination of the disease, are costly invasive methods namely SPECT and CT tomography’s which are effective, essentially, in the mature stage of the disease. Besides classic methods, practitioners adopt several diagnostic paths. Some of them were based on handwriting by considering the relationship between handwriting and nervous system problems. Others have relied on peripheral biomarkers for early detection of PD.
The detection of Parkinson's disease is based on the use of different classifiers. The distinction between them is based on measurement criteria, namely classification accuracy, F1-score , Recall, Precision, R2-score ... etc. Each of these measurement criteria has formulas to calculate it and conclude which is the most qualitatively adequate classifier for the study. Before defining these criteria, we must focus on the confusion matrix Called a contingency table, it is a tool for measuring the performance of a learning model, checking how far its predictions are correct, compared to reality in classification problems.
II. METHODOLOGY
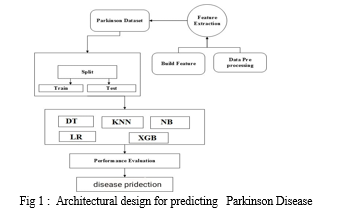
A. Data Collection
Parkinson Disease Datasets
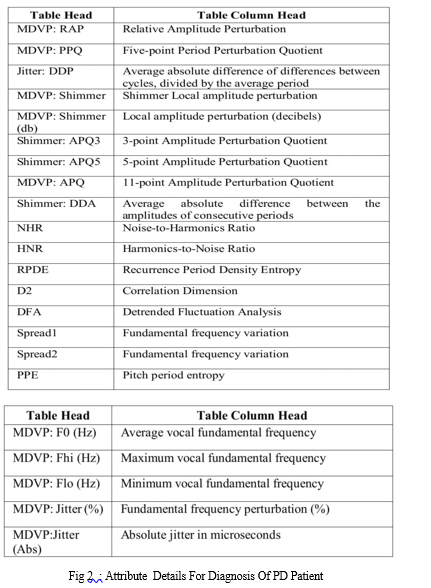
In this Project, we used the Parkinson disease data from provided by the UCI Machine Learning Repository this dataset is consisting of 195 patient data with 23 features of voice data set is used.
'https://archive.ics.uci.edu/ml/machine-learning-databases/parkinsons/parkinsons.data'
B. Data Pre-processing
In this section, firstly we extracted features from the Parkinson disease datasets. We picked the 23 columns and 195 entries of data. Then missing data and huge number of functions in the data collection, the data is very challenging to use effectively. This technique eliminates duplicate information, conflicting data, noisy, incomplete data, and. To boost the network's classification efficiency and redundant values. They are 23 features from the dataset which were we collected. There is no duplicate data is present in this dataset and no columns of the dataset contains any Missing Values.
C. Machine learning Thecniques
- Decision Tree Classifier: Decision Tree is a Supervised learning technique that can be used for both classification and Regression problems, but mostly it is preferred for solving Classification problems. It is a tree-structured classifier, where internal nodes represent the features of a dataset, branches represent the decision rules and each leaf node represents the outcome. In a Decision tree, there are two nodes, which are the Decision Node and Leaf Node. Decision nodes are used to make any decision and have multiple branches, whereas Leaf nodes are the output of those decisions and do not contain any further branches. The decisions or the test are performed on the basis of features of the given dataset.
- Logistic Regression: Logistic Regression was mostly used in the biological research and applications in the early 20th century (Jr, Lemeshow, & Sturdivant, 2013). Logistic Regression (LR) is one of the most used machine learning algorithms that is used where the target variable is categorical. Recently, LR is a popular method for binary classification problems. Moreover, it presents a discrete binary product between 0 and 1. Logistic Regression computes the relationship between the feature variables by assessing probabilities (p) using underlying logistic function.
- Naive Bayes: Naïve Bayes algorithm is a supervised learning algorithm, which is based on Bayes theorem and used for solving classification problems. It is mainly used in text classification that includes a highdimensional training dataset. Naïve Bayes Classifier is one of the simple and most effective Classification algorithms which helps in building the fast machine learning models that can make quick predictions. It is a probabilistic classifier, which means it predicts on the basis of the probability of an object.
- KNN Classifier: K-Nearest Neighbour is one of the simplest Machine Learning algorithms based on Supervised Learning technique. K-NN algorithm assumes the similarity between the new case/data and available cases and put the new case into the category that is most similar to the available categories. K-NN algorithm stores all the available data and classifies a new data point based on the similarity. This means when new data appears then it can be easily classified into a well suite category by using K- NN algorithm. K-NN algorithm can be used for Regression as well as for Classification but mostly it is used for the Classification problems.It is also called a lazy learner algorithm because it does not learn from the training set immediately instead it stores the dataset and at the time of classification, it performs an action on the dataset. KNN algorithm at the training phase just stores the dataset and when it gets new data, then it classifies that data into a category that is much similar to the new data.
- XGBoost Classifier: XGBoost is a popular and efficient open-source implementation of the gradient boosted trees algorithm. Gradient boosting is a supervised learning algorithm, which attempts to accurately predict a target variable by combining the estimates of a set of simpler, weaker models. XGBoost may be formally defined as a decision tree-based ensemble learning framework that uses Gradient Descent as the underlying objective function and comes with a lot of flexibility while delivering the desired results by optimally using computational power.
D. Evaluation Criteria
In this work, we used five supervised learning techniques for the detection of Parkinson disease. Therefore, the performance measurements of the classifiers are evaluated by different statistical procedures. Such as Recall, Precision, F1-Score and R2-Score etc.
Hence, the computation method of the measurement considerations are as follows.
???????????????????????????????????? = ????????/ ???????? + ????P
???????????????????????????????? = ???????? + ????????/ ???????? + ???????? + ???????? + ????????
Recall or sensitivity = ???????? / (???????? + )
???????????????????????? = 2 ∗ ???????????????????????????????????? ∗ ????????????????????????????????????????????/ ???????????????????????????????????? + ????????????????????????????????????y
III. RESULTS AND DISCUSSION
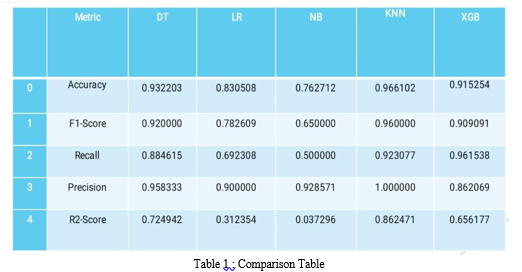
Here we have evaluated the five-machine learning supervised algorithms for detection of Parkinson Disease. The analysis of five classification techniques were evaluated and we have got different accuracy with different algorithm.
In this section we have lead a comparison between five different machine learning classifier where we have compared the Accuracy, Precision ,F1-Score,Recall and R2-Score values which we have got by this analysis.
IV. ANALYSIS OF RESULTS
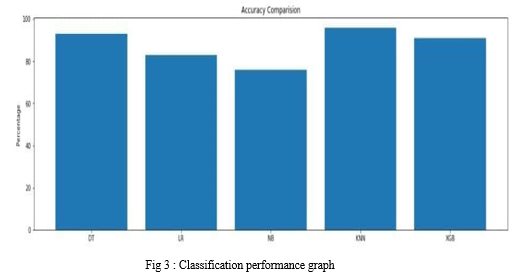
According to the performance measurements of three classification algorithms are presented in figure. The results clearly show that the KNN reached to the highest accuracy (96%) and DT achieved the second highest accuracy. where as Naive Bayes has achieved lowest accuracy (76%), respectively. Finally, KNN is the highest performer by overall performance.
Conclusion
In this analysis, we have illustrated five supervised learning machine learning approaches. Afterwards, we evaluated the performance of the five classifiers which are used in the prediction of Parkinson disease and assessed their performance using different statistical methods. The tentative performance shows that the KNN have achieved the highest performance than the other four classifiers within the Parkinson datasets. It is 96%.hence we can say that KNN perform good comparative to other classifier . This analysis has used five machine learning techniques for the detection of Parkinson disease based on several parameters. this application will be able to detect in Parkinson disease in very few minutes and notify dangerous probability of having disease. In very minimal steps we can predict the person is healthy or PD patient.
References
[1] Basil K Varghese, Geraldine Bessie Amali D*, Uma Devi K S “Prediction of Parkinson’s Disease using Machine Learning Techniques on Speech dataset” year- Feb 2019. [2] Timothy J. Wroge1 , Yasin Ozkanca ¨ 2 , Cenk Demiroglu2 , Dong Si3 , David C. Atkins4 and Reza Hosseini Ghomi “Parkinson’s Disease Diagnosis Using Machine Learning and Voice”. [3] Antonio Suppa1,2†, Giovanni Costantini 3†, Francesco Asci 2 , Pietro Di Leo3 , Mohammad Sami Al-Wardat 4 , Giulia Di Lazzaro5 , Simona Scalise6 , Antonio Pisani 7,8 and Giovanni Saggio3 * “ voice in parkinson’s disease: A Machine learning study ” year- Feb 2022 . [4] Shrihari K Kulkarni1, K R Sumana2 “Detection of Parkinson’s Disease Using Machine Learning and Deep Learning Algorithms” year- Aug 2021. [5] Md. Sakibur Rahman Sajal1,2* , Md. Tanvir Ehsan1,2, Ravi Vaidyanathan3 , Shouyan Wang4 , Tipu Aziz5 and Khondaker Abdullah Al Mamun1,2 ”Telemonitoring Parkinson’s disease using machine learning by combining tremor and voice analysis” year-2020. [6] “Parkinson’s Disease Diagnosis: Detecting the Effect of Attributes Selection and Discretization of Parkinson’s Disease Dataset on the Performance of Classifier Algorithms”- Gamal Saad Mohamed. Year- Nov 2016. [7] R. Prashanth and S. D. Roy, ‘‘Early detection of Parkinson’s disease through patient questionnaire and predictive modelling,’’ Int. J. Med. Informat., vol. 119, pp. 75–87, Nov. 2018. [8] H. Gunduz, ‘‘Deep learning-based Parkinson’s disease classification using vocal feature sets,’’ IEEE Access, vol. 7, pp. 115540–115551, 2019. [9] S. Lahmiri and A. Shmuel, ‘‘Detection of Parkinson’s disease based on voice patterns ranking and optimized support vector machine,’’ Biomed. Signal Process. Control, vol. 49, pp. 427–433, Mar. 2019. [10] D. Braga, A. M. Madureira, L. Coelho, and R. Ajith, ‘‘Automatic detection of Parkinson’s disease based on acoustic analysis of speech,’’ Eng. Appl. Artif. Intell., vol. 77, pp. 148–158, Jan. 2019. [11] V. Illner, P. Sovka, and J. Rusz, ‘‘Validation of freely-available pitch detection algorithms across various noise levels in assessing speech captured by smartphone in Parkinson’s disease,’’ Biomed. Signal Process. Control, vol. 58, Apr. 2020, Art. no. 101831
Copyright
Copyright © 2022 Amreen Khanum D, Prof. Kavitha G, Prof. Mamatha H S . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET46272
Publish Date : 2022-08-11
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online