

Ijraset Journal For Research in Applied Science and Engineering Technology
Text Summarization and Conversion of Speech to Text
Authors: Prof. Priyanka Abhale, Dawood Dalvi, Sibin Alex, Aman Jham, Viraj Akte
DOI Link: https://doi.org/10.22214/ijraset.2023.52902
Certificate: View Certificate
Abstract
This article describes the fusion of recurrent neural networks and deep learning algorithms for text summarization systems and analysis of the text learning process. Next, the text analytics learning model is summarized. In addition, applications of deep learning-based text analysis are also introduced. Language is the most important part of communication between people. Although there are many ways to express our thoughts and feelings, language is considered the most important medium of communication. Speech recognition is the process by which machines recognize different people\'s voices based on specific words and phrases. End-to-end deep learning techniques can be used to identify and simplify spatial representations of text data and semantic information. This study considers text analysis based on deep learning
Introduction
I. INTRODUCTION
The Text Summary helps you create a summary report of the given paraphrasing. Differences in pronunciation are clearly visible in each person's speech. Voice is the easiest way to communicate, but speech recognition has some problems: Fluency, Pronunciation, Broken Words, Stuttering, etc. All these issues must be considered when processing audio. Long documents take time and are difficult to read and understand. Text synopsis solves this problem by providing a shortened synopsis with semantics.
A. Segmentation
The task of dividing text into meaningful segments is called text segmentation. These segments consist of words, phrases, or topics. Topic segmentation, a type of text segmentation task that divides long texts into sections corresponding to specific topics or subtopics, is part of our research. For example, consider automatic transcription of a one-hour podcast. Transcripts can be long, so it's easy to lose track of what you're reading. The Automatic Topic Splitter solves this problem by splitting the text into several segments, making the transcription easier to read.
B. Normalization
An important part of data management is data cleansing. As part of the data cleansing process, all database content is checked and missing, inaccurate, duplicate, or irrelevant information is updated or deleted. Data cleansing is finding techniques that improve the accuracy of a data set without necessarily affecting the existing data. It doesn't just remove old information to make room for new data. The process of identifying and correcting bad data is called data sanitization. Most of the work that organizations do is data driven, but few do it effectively. The most important phases of data processing are data cleansing, classification, and standardization.
C. Feature Extraction
The goal of feature extraction is to reduce the amount of resources required to describe large amounts of data. One of the main problems in analyzing complex data is the sheer number of variables involved. Results can be improved using a built set of application-dependent functions, often written by experts. Analyzes involving large numbers of variables typically require large amounts of memory and computing power. Feature engineering is one of them.
D. Modelling
Modeling is about teaching a machine learning algorithm to predict labels from features, adapting it to your business needs, and validating it. Computer models use deep learning to learn how to perform classification tasks directly from text or speech. Natural Language Processing (NLP) uses text summarization techniques to provide concise and accurate summaries of referenced documents.
Summarizing long articles by hand is very difficult. Machine learning-based text summarization remains an extensive research area. Statistical modeling techniques are used to identify hidden topics and keywords within groups of essays. A probabilistic approach to learning, analyzing, and retrieving topics from document collections is topic modeling. LDA is most commonly used for extracting summaries of multiple documents to verify that the extracted sentences accurately capture the ideas of the input documents. This article describes a text summarization approach to reduce redundancy and improve the scope of the final summary.
II. OBJECTIVE
The purpose of automatic text summarization is to present the original material in a semantically concise format. The main advantage of summaries is that they shorten the reading process. His two types of text summarization techniques are:
Extractive and abstract. Selecting key sentences, paragraphs, etc. from the original content and concatenating them into a short version constitutes the extractive summarization technique. Understanding the key ideas in a document and expressing those ideas in plain, everyday language constitutes an abstract summary.
III. SYSTEM ARCHITECTURE
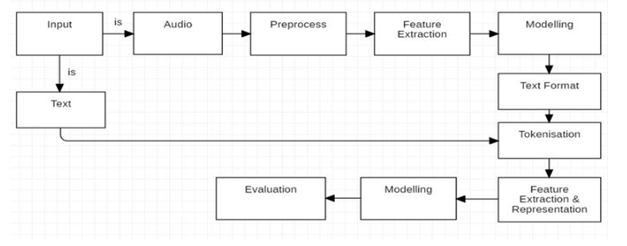
IV. ACKNOWLEDGMENT
This paper is supported by Alard College of Engineering ,Pune 411057. We would like to thank all those who have contributed invaluably to the completion of this workshop report on Speech-to-Text and Text Summary as part of our curriculum. We would like to express our sincere gratitude to everyone in the cooperation department for their tremendous support and guidance in developing the system. We would like to thank Professor Priyanka Abhare for guiding us in the right direction, taking the time to clear our doubts whenever needed, and sharing her knowledge and experience in implementing this project. I am very grateful and would like to express my gratitude.
Conclusion
In this research paper, we have successfully studied text-to-speech conversion and created a summary of this text. This model can be used in the implementation of extended business meetings where one can get summary information about a particular meeting.
References
[1] Jose D V, Alfateh Mustafa, Sharan R, \"A Novel Model for Speech to Text Conversion,\" International Refereed Journal of Engineering and Science (IRJES), vol 3, no. 1, 2014. [2] K. M. Shivakumar, V. V. Jain and P. K. Priya, \"A study on impact of language model in improving the accuracy of speech to text conversion system,\" 2017 International Conference on Communication and Signal Processing (ICCSP), Chennai, pp. 1148-1151, 2017. [3] Y. H. Ghadage and S. D. Shelke, \"Speech to text conversion for multilingual languages,\" 2016 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, pp. 0236-0240, 2016. [4] Umar Nasib Abdullah, Kabir Humayun, Ahmed Ruhan, Uddin Jia., \"A Real Time Speech to Text Conversion Technique for Bengali Language,\" 2018 International Conference on Computer, Communication, Chemical, Material and Electronic Engineering (IC4ME2), pp. 1-4, 2018. [5] G. E. Hinton, R. R. Salakhutdinov, “Reducing the Dimensionality of Data with Neural Networks”[J], Science, 2006, 313(5786):504-507. [6] C. Raffel,D. P. W. Ellis ,“Feed-forward Networks with Attention Can Solve Some Long-term Memory Problems”[OL],arXiv Preprint, arXiv: 1512. 08756. [7] Y. Lecun,L. Bottou,Y. Bengio,“Gradient-based Learning Applied to Document Recognition”[J],Proceedings of the IEEE, 1998, 86(11):2278- 2324. [8] A. Severyn,A. Moschitti,“Twitter Sentiment Analysis with Deep Convolutional Neural Networks”[C],Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile ,2015: 959-962. [9] Z. G. Jin,B. H. Hu,R. Zhang,“Analysis of Weibo Sentiment with Multidimensional Features Based on Deep Learning”[J],Journal of Central South University (Science and Technology), 2018, 49(05):1135-1140. [10] X. Zhang,J. Zhao,Y. Lecun, “Character-level Convolutional Networks for Text Classification”[C],Advances in neural information processing systems, New York, USA,2015: 649-657.
Copyright
Copyright © 2023 Prof. Priyanka Abhale, Dawood Dalvi, Sibin Alex, Aman Jham, Viraj Akte. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET52902
Publish Date : 2023-05-24
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online