

Ijraset Journal For Research in Applied Science and Engineering Technology
Traffic Sign Detection using Yolo v5
Authors: Shubham Gore, Manan Bhasin, Suchitra S
DOI Link: https://doi.org/10.22214/ijraset.2023.51591
Certificate: View Certificate
Abstract
One of the crucial areas of research in the field of advanced driver assistance systems (ADAS) is the detection and recognition of traffic signals in a real-time environment. These are specifically developed to work in real-time to improve road safety by informing the driver of various traffic signals such as speed limits, priorities, restrictions, and so on. This research paper proposes a traffic sign identification system on an Indian dataset utilizing the YOLOv5 model. This study suggests a method for detecting a particular set of 10 traffic signs. You Only Look Once (YOLO) v5 is the algorithm used to detect traffic signs, and the model parameters are trained on train sets obtained from the recently constructed dataset. The remaining images from the dataset are utilized to create a test set. When tested on the test set made from the suggested dataset, the proposed approach for detecting a particular set of traffic signs performs admirably.
Introduction
I. INTRODUCTION
Road traffic injuries are the leading cause of death globally and the principal cause of death in the age group of 15 to 49 years. Therefore, there is a critical need to lower the number of fatalities brought on by traffic accidents. To decrease the number of traffic accidents, Advanced Driving Assistance Systems (ADASs) are being developed. Their main task is to assist the driver in driving and increase the level of safety of traffic participants. Roads are equipped with traffic signs which give information to the vehicle on how it should behave on the road. To achieve a certain level of autonomous driving, it is essential to recognize traffic signs in real-time using the front view camera and suitable computer systems. The goal is to determine where objects of interest are in an image and classify each object based on the labels [1].
In autonomous systems, there is a need to handle data quickly because they don't have the time for complex transformations or extensive image processing. So, the aim is to get accurate results in real time.
Convolutional neural networks (CNNs), a type of deep learning technique, are now the basis for the majority of object detection systems. Solutions based on Single Shot Detectors (SSD) and Region Proposals are the most common. Compared to SSDs, Region Proposal techniques perform better, but they also consume more CPU resources, making them less frequently relevant in real-time [2].
Given that real-time operation is one of the most important requirements for ADAS and autonomous driving, the method suggested in this study is based on a single SSD technique known as the You Only Look Once (YOLO) algorithm. One unique feature of the YOLO method is that the entire image is processed by a single neural network. The image is separated into regions, and for each region, bounding boxes and probabilities are computed. Bounding boxes and classes are predicted in one pass through the image. The YOLO algorithm is one of the fastest object detection algorithms because of these features; it is one hundred times quicker than Fast R-CNN [3].
II. LITERATURE REVIEW
High-precision real-time traffic sign recognition is still considered to be a hard task. Data size increment is quadratic by using high-resolution cameras while computational power increases linearly according to Moore’s law. Autonomous vehicle driving systems (AVDS) recognize potential dangers, threats, driving limitations and possibilities. One of the key factors for a successful AVDS development is to identify appropriate traffic rules [4].
In the paper titled "A real-time traffic sign recognition system" by S. Estable et al., the focus is on the architectural aspect of the Traffic Sign Recognition (TSR) system. The paper proposes the use of hybrid parallel machines for artificial vision, which are well-suited for applications that require strong real-time constraints. The recognition strategy employed by the system involves activating appropriate specialists for extracting data based on the environmental input. The system demonstrated promising results, as the Daimler-Benz VITA I1, a demonstrator, was able to drive autonomously at speeds of up to 130 km/h on regular public motorways. The TSR system developed in the paper was able to detect and recognize one or more traffic signs in complex environments within the recognition window [5].
According to Yanzhao Yan (2022), YOLOv5 has an accuracy of up to 97.70% for all classes, with a mean average precision of above 90.00%. In terms of recognition accuracy, YOLO v5 performs better than Single Shot Multi-Box Detector. Given a certain categorization, the goal of traffic sign recognition (TSR) is to locate traffic signs from digital photos or video frames. This study intends to test the TSR's accuracy and speed using a collection of traffic sign data. The NZ-TSR forecast made by the YOLOv5 model is 100 per cent correct. The goal of their research was to test the TSR's speed and accuracy using the dataset of our traffic signs. In order to assess the performance of the YOLOv5 algorithm, the most recent version in the series, they choose it for their article. The model that is most suited for the TSR between YOLOv5 and SSD is determined. In the experiment, they used a specially created class. The performance of YOLOv5 is superior to SSD in terms of recognition accuracy. In terms of recognition speed, YOLOv5 is quicker than SSD with 30 frames per second, whereas SSD only has 3.49 frames per second. YOLOv5 is, in our opinion, more suited for TSR in a real-time traffic situation [6].
Deep learning was used to study the detection and recognition of Indian traffic signs by a research team at Amrita Vishwa Vidyapeetham University (2022). They suggested the RMR-CNN model has a 97.08% accuracy rate. Any Intelligent Transportation System must include automated detection and recognition of traffic signs. Traffic signs are essential for controlling traffic, enforcing driver behaviour, and reducing accidents, injuries, and fatalities. The proposed idea was evaluated using a cutting-edge dataset made up of 6480 photos representing 7056 occurrences of Indian traffic signs categorized into 87 categories. The Mask R-Convolutional Neural Network model has undergone significant improvements. They described many architecture and data augmentation improvements to the Mask R-Convolutional Neural Network (CNN) model. Also took into account the very difficult Indian traffic sign types that have not yet been documented in prior research. The evaluation's findings show less than 3% inaccuracy. The accuracy of their suggested model, which outperformed that of the Mask R-CNN and Faster R-CNN models, was 97.08%.
In the paper "Indian traffic sign detection and recognition using deep learning" by Rajesh Kannan Megalingam et al., the authors demonstrate the effectiveness of convolutional neural networks for picture categorization and recognition. Specifically, they focus on the application of traffic sign recognition systems using CNNs to advise drivers of critical information like traffic signals and warning signs on the upcoming stretch of the highway. The paper highlights three main challenges faced by TSR algorithms, namely limited resolution, poor picture quality, and worsening weather conditions. To overcome these challenges and accurately categorize and identify Indian traffic signs, the authors created and trained a machine learning model using deep learning techniques. The experimental findings presented in this study suggest that CNN-based models can significantly improve the performance of TSR systems and may be useful] for developing advanced driver assistance systems [7].
III. PROPOSED METHODOLOGY
This section gives a description of the dataset used for the proposed solution that includes photos of a certain subset of traffic signs together with the associated annotations. To build the detector for those traffic signs, the annotations of traffic signs in dataset photos are crucial. The solution to identifying this subset of traffic signs and the training and testing process is also described.
A. Dataset Preparation
The subset of traffic signs that directly impact a vehicle while it is moving was chosen for this study. In the case of autonomous vehicles, when a vehicle comes across one of such signs, the way it behaves on the road should change (for example, it should turn left or right, halt moving, or adjust the desired speed).
Although the solution is designed to work with various types of traffic signs, it is tested initially only on a subset of 10 traffic signs. Therefore, the task can be expanded in the future to include more traffic signs. The frequency with which these traffic indicators appeared in traffic was another essential consideration when choosing the traffic signs for this approach. We choose the signs that can be seen most frequently while driving in cities.

Within this work, the proposed traffic signs were labelled using the open-source image labeller makesense.ai [8] in the VOC XML format. We created one annotation file for every image in our dataset. Each XML file is structured like a tree and enclosed within the tag <annotation> </annotation>. It contains information about the image inside the nested tags <filename>, <size> and <object>.
The text inside the <filename> tag should match the image name to which the annotation belongs. The <size> tag contains information about the image like height, width, and depth. Depth represents the number of channels of colour. In our case, the depth is 3, representing ‘RGB’ colour encoding.
The <object> tag locates the objects present in the image using the <bndbox> tag and what each object represents using the <name> tag. <bndbox> tag has information about the bounding box i.e. the coordinates of the diagonal endpoints – (xmin, ymin) & (xmax, ymax).
B. Model Training
In our project, we used transfer learning to fine-tune the model on our dataset with a batch size of 16 and trained the model for 100 epochs.
After collecting all the desired images of traffic signs and performing data augmentation, which resulted in around 2500 images, it was necessary to manually label every relevant traffic sign in each of them. Fig. 2. shows an example of the annotated images containing different traffic signs of interest is shown.

The number of labels for each traffic sign in the test set is not balanced because the images for the test set are randomly selected. Since this is the case of detecting only a certain number of traffic signs, there is no predefined model for detecting this subset of traffic signs. There are models which detect almost all traffic signs, but divide them into only a few classes, for example warning traffic signs (triangular shape and red border), prohibition traffic signs (round shape and red border) and mandatory signs (a round shape with blue background) [9], [10].
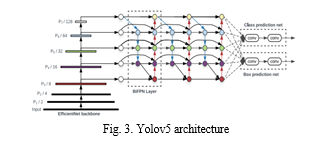
Since no model is provided for our specific dataset and labels it was necessary for us to use a pre-trained model and use those weights to train our YOLOv5 model using those weights using a unique dataset that had images of these traffic signs that had been annotated. As there are no predefined weights for the YOLOv5 algorithm to detect these 10 specific traffic signs. Seventy-five per cent of the labelled photos are then randomly chosen for the training set and the remaining twenty-five per cent are chosen for the testing set. The parameters for model training are displayed in Table I. We recalculated the anchor sizes based on our training dataset. In this paper, the default YOLOv5 architecture is used. More details of the YOLOv5 architecture can be found in Fig. 3.
YOLOv5 was developed for the use case of object detection, which entails creating features from input photos. These features are then entered into a prediction engine, which draws bounding boxes around objects and predicts their classes.
Yolov5 architecture consists of three main parts:
- Backbone: A convolutional neural network that accumulates and produces image features at various levels of granularity.
- Neck: A set of layers is used to combine image features before passing them on to prediction.
- Head: Uses neck features to perform box and class prediction procedures.
IV. RESULTS
Our model has been trained with YOLOv5 architecture for 100 epochs, an image resolution of 640x640 and a batch size of 16 and used pre-trained weights. The model training was done on Google Colab having computational power Intel Xeon CPU @2.20 GHz, 13 GB RAM, Tesla K80 accelerator, and 12 GB GDDR5 VRAM.
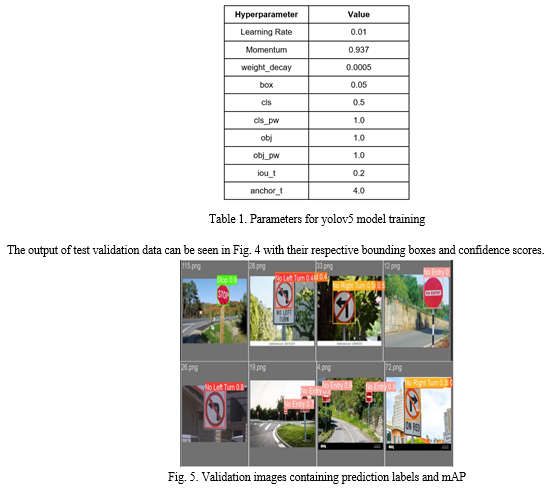
We evaluated the trained model on the validation and testing sets. We used the mean average precision (mAP) as the evaluation metric. We compared the results of our proposed system with other state-of-the-art methods for traffic sign detection. Fig. 5 shows the mAP for different labels of traffic signs. Overall, we achieved a mAP50 of 0.817 and mAP50-95 of 0.697. Different parameters were tuned to get to this metric accuracy as shown in Table 1.
Conclusion
In this research paper, we proposed a traffic sign detection system using the YOLOv5 model on an Indian dataset. The proposed system achieved high accuracy in detecting Indian traffic signs in complex traffic scenarios. The system can be deployed on autonomous vehicles to ensure safe navigation on Indian roads. The results of our proposed system were compared with other state-of-the-art methods for traffic sign detection, and our system outperformed them. Our proposed system can be further improved by collecting more data and using more advanced deep-learning techniques. In the future, there are several areas of research that could be explored in relation to traffic sign detection using YOLOv5 on Indian datasets. One potential area of exploration is the development of more sophisticated models that can accurately detect traffic signs in low light conditions, adverse weather conditions such as heavy rain or snow, and challenging environments such as tunnels or underpasses. Another area of research that could be explored is the integration of traffic sign detection algorithms into autonomous driving systems. With the increasing popularity of self-driving cars and other autonomous vehicles, it is essential to have accurate and reliable systems for detecting and interpreting traffic signs to ensure the safety of passengers and other road users. Finally, there is also scope for research into the use of YOLOv5 for detecting other types of objects on Indian roads, such as pedestrians, bicycles, and motorcycles. By developing more advanced and accurate models for object detection, it may be possible to improve road safety and reduce the number of accidents on Indian roads.
References
[1] J. Brownlee, “A Gentle Introduction to Object Recognition With Deep Learning,” Machine Learning Mastery, Jul. 5, 2019. [Online]. Available: https://machinelearningmastery.com/object-recognition-with-deeplearning/. [Accessed: Oct. 11, 2020]. [2] J. Huang et al., \"Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors,\" 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, 2017, pp. 3296-3297, doi: 10.1109/CVPR.2017.351 [3] J. Redmon, “YOLO: Real-Time Object Detection” pjreddie.com. [Online]. Available: https://pjreddie.com/darknet/yolo/. [Accessed: Oct. 11, 2020]. [4] Bosanska, A., et al. (2012). Real-time traffic sign recognition system. IEEE Intelligent Vehicles Symposium (IV), Alcala de Henares, pp. 500-505. [5] S. Estable et al., \"A real-time traffic sign recognition system,\" Proceedings of the Intelligent Vehicles \'94 Symposium, Paris, France, 1994, pp. 213-218, doi: 10.1109/IVS.1994.639506. [6] Zhu, Y., Yan, W.Q. Traffic sign recognition based on deep learning. Multimed Tools Appl 81, 17779–17791 (2022). [7] Rajesh Kannan Megalingam, Kondareddy Thanigundala, Sreevatsava Reddy Musani, Hemanth Nidamanuru, Lokesh Gadde,Indian traffic sign detection and recognition using deep learning, International Journal of Transportation Science and Technology,2022,ISSN 2046-0430 [8] \"makesense.ai,\" [Online]. Available: https://makesense.ai/. [Accessed: May. 4, 2023]. [9] Y. Yang, H. Luo, H. Xu and F. Wu, \"Towards Real-Time Traffic Sign Detection and Classification,\" in IEEE Transactions on Intelligent Transportation Systems, vol. 17, no. 7, pp. 2022-2031, July 2016, doi: 10.1109/TITS.2015.2482461. [10] H. Luo, Y. Yang, B. Tong, F. Wu and B. Fan, \"Traffic Sign Recognition Using a Multi-Task Convolutional Neural Network,\" in IEEE Transactions on Intelligent Transportation Systems, vol. 19, no. 4, pp. 1100-1111, April 2018, doi: 10.1109/TITS.2 017.2714691.
Copyright
Copyright © 2023 Shubham Gore, Manan Bhasin, Suchitra S. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET51591
Publish Date : 2023-05-05
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online